Blog
Semantička pretraga dokumenata
Pretraživanje sadržaja je aktivnost koju svi redovito radimo u privatne i poslovne svrhe, bilo da se radi o pretraživanju baza podataka, dokumenata ili web stranica. Za razliku od pretraživanja papirnatih dokumenata, gdje je jedini način da pronađemo određeni sadržaj da pročitamo sve dokumente koje pretražujemo, digitalizacijom smo uvelike smanjili vrijeme i količinu obavljanja takvih zadataka.
Samo pretraživanje digitalnog sadržaja krenulo je vrlo jednostavno, pretragom točno unesenog teksta (tzv. leksička pretraga). Kasnije se pokazalo da takva vrsta pretraživanja nije uvijek efikasna zbog bogatstva i složenosti različitih jezika. Da bi samo pretraživanje bilo još bolje i prilagođenije jeziku pretraživanja uvela se semantička pretraga. Prelaskom na semantičku pretragu dokumenata pretraživanje se obavlja ne samo tražeći postojanost riječi u dokumentu već uzimajući u obzir i značenje samih riječi. Cilj semantičkog pretraživanja je poboljšati točnost rezultata pretraživanja razumijevanjem korisničkih namjera, kontekstualnog značenja unesenog termina te povezanosti samih riječi.
Leksička pretraga vs. semantičko pretraživanje
Leksičkom pretragom pretražuju se samo točna podudaranja riječi u nekom dokumentu ili bazi pretraživanja. Takvim se pretraživanjem često koristimo, primjerice kada pretražujemo neku web stranicu ili PDF dokument pomoću naredbe za pretraživanje. U tom slučaju uvijek moramo paziti na oblik riječi koji pretražujemo pa smo skloni napisati korijen riječi kako bismo dobili sva bliska pretraživanja.
Zamislimo li da tako pretražujemo web sadržaj pomoću najpoznatije web tražilice Google, vrlo brzo ne bismo bili zadovoljni rezultatima koje nam ona izbacuje. Google nam omogućuje da isprobamo točno podudaranje riječi ukoliko upit napišemo unutar navodnika, primjer na Slici 1. U ovom primjeru možemo vidjeti da za upit „prodaja apartmana u zagrebu“ tražilica ne bi izbacila niti jedan rezultat, budući da ne postoji niti jedna web stranica koja ima napisan točno takav izraz.
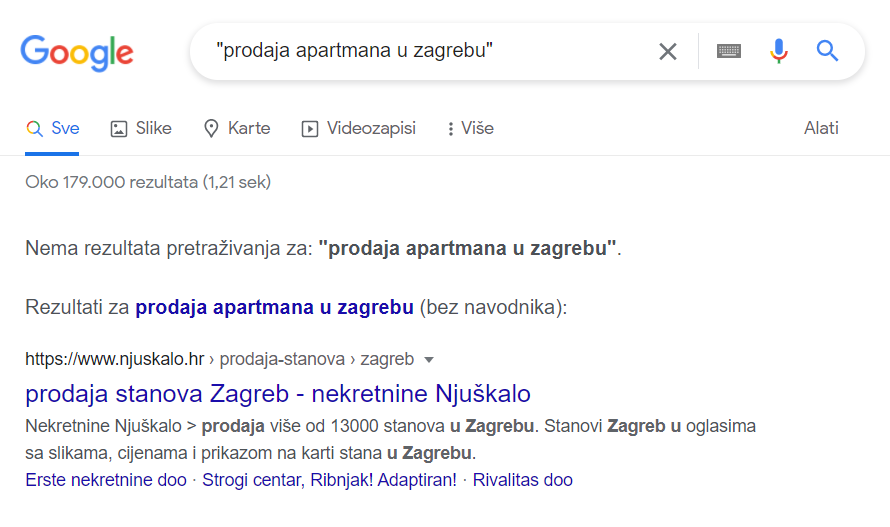
No kako je Google uistinu pametna tražilica, automatski nam nudi da pretražimo upit bez navodnika i pronađemo sve iste i kontekstualno slične tj. jednake upite. U takvom slučaju, dobit ćemo oko 179 000 rezultata. Razlog tome je što u tom slučaju Google uzima u obzir sve sinonime, izraze, poretke riječi i drugo kako bi dao najbolji rezultat našeg pretraživanja. Nama je jasno da ukoliko pitamo za “prodaju apartmana u zagrebu” da je to isto kao da pitamo “kupnja apartmana u zagrebu”, “novi stan u zagrebu”, “prodaja nekretnina u području grada Zagreba“, no kako to zna Google ili neki drugi pretraživač? Jedan od odgovora krije se u semantičkom pretraživanju (Google i drugi napredni pretraživači koriste i brojne druge tehnike prilikom pretraživanja web stranica, no to nije tema ovog bloga pa to nećemo detaljno razmatrati).
Komponente semantičkog pretraživanja
Važna komponenta semantičkog pretraživanja je semantičko označavanje. Ono obogaćuje sadržaj informacijama koje se mogu strojno obraditi povezivanjem postojećih informacija s izdvojenim pojmovima. Ti pojmovi izvučeni iz dokumenata su nedvosmisleno definirani i povezani jedni s drugima unutar i izvan sadržaja. Semantičko označavanje vrši se korištenjem tehnika računalne obrade prirodnog jezika (engl. Natural Language Processing, NLP) koje pomažu pri prevođenju i pretvorbi teksta u strukturirane podatke.
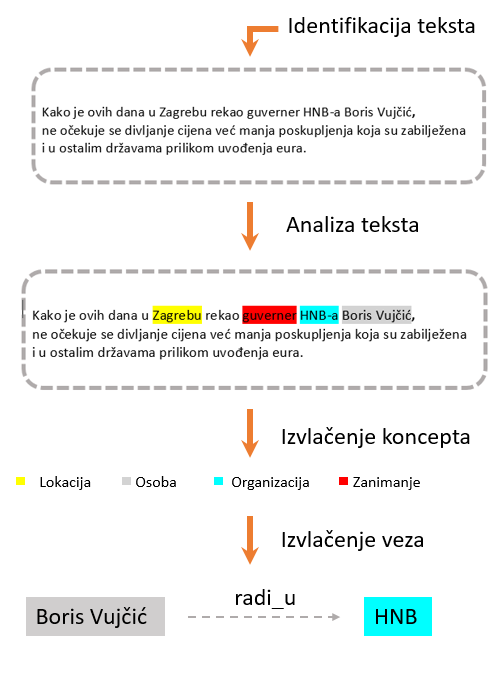
Osim semantičkog označavanja važna komponenta pri semantičkom pretraživanju je i latentno semantičko indeksiranje (engl. Latent Semantic Indexing, LSI). LSI je tehnika u obradi prirodnog jezika koja analizira odnose između skupa dokumenata i pojmova koje oni sadrže identificirajući skrivene kontekstualne odnose između riječi. Drugim riječima, LSI se zasniva na principu tako da riječi koje se koriste unutar istog konteksta pretežito imaju isto ili povezano značenje iako ne dijele iste znakove ili sinonime.
IBM Watson Discovery
IBM Watson Discovery je IBM-ov alat za inteligentno semantičko pretraživanje podataka pomoću umjetne inteligencije. Također, predstavlja i platformu za analizu teksta koja koristi NLP kako bi otkrila korisne podatke iz složenih poslovnih dokumenata, web stranica ili velikih skupova podataka te tako skratila vrijeme samog pretraživanja. IBM Watson Discovery omogućava korisnicima da dodaju vlastite skupove dokumenata te nad njima primjenjuje algoritme koji obogaćuju umetnute podatke izvlačeći ključne pojmove i entitete (poput lokacija, organizacija, osoba itd.) te provodi semantičku analizu nad dokumentima.
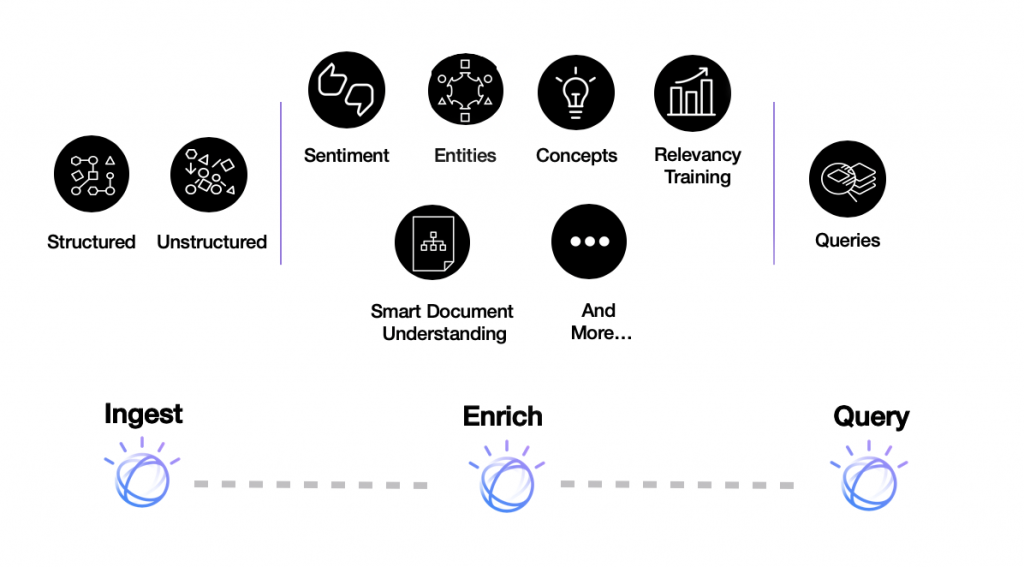
IBM Watson Discovery obogaćuje podatke dodavanjem metapodataka iz prikupljenih semantičkih informacija. Podaci se prikupljaju pomoću četiri glavne IBM Watson funkcije, a to su izdvajanje entiteta, analiza osjećaja, klasifikacija kategorija i označavanje koncepata. Također, integriran je i pametni alat za razumijevanje dokumenata (engl. Smart Document Understanding, SDU). SDU je alat baziran na algoritmima strojnog učenja koji razbija dokumente u manje komade informacija te omogućuje korisniku da jednostavno kategorizira dijelove dokumenata kako bi alat mogao izgraditi bolje razumijevanje kritičkih komponenata unutar danih dokumenata te poboljšati rezultate odgovora prilikom pretraživanja.

Nakon prijenosa podataka i njihovog obogaćivanja moguće je graditi upite te integrirati IBM Watson Discovery u vlastita rješenja ili s drugim IBM-ovim alatima poput servisa IBM Watson Natural Language Understanding ili IBM Watson Assistanta. IBM Watson Discovery implementiran je u IBM Watson Assistant preko Search Skilla te omogućuje virtualnom asistentu da odgovara na složena pitanja pregledavajući veliku bazu dokumenata. IBM Watson Discovery dostupan je na preko 20 svjetskih jezika uključujući i hrvatski jezik te ga je moguće koristiti on-premise ili na cloudu.
Zaključak
Semantičko pretraživanje omogućilo je da se pretraživanje više ne temelji isključivo na postojanju riječi u dokumentima već da se pretražuje značenje tih riječi tj. upita. Drugim riječima, cilj semantičkog pretraživanja je znati zašto korisnik pretražuje upravo te ključne riječi i što namjerava učiniti s dobivenim podacima. Takav način pretraživanja približava računalno pretraživanje dokumenata ljudskom načinu razmišljanja uzimajući u obzir različite načine i tonove upita. Semantičko pretraživanje uvelo je revoluciju u tražilicama što se pokazuje u njegovoj širokoj uporabi ne samo kod web pretraživača već i kod pretraživača baza znanja specijaliziranih za različite znanosti i poslovanja.

