Blog
SQream baza podataka – za najbrži uvid u podatke
SQream je hibridna analitička platforma koja vam daje uvide koji su vam potrebni, kada su vam potrebni – na podacima bilo koje veličine

SQream DB je moderna RDBMS baza primarno zamišljena za data warehousing velike količine podataka (Big Data) s dodatnim ubrzanjem preko grafičkih procesora (GPU). Primarno objavljena 2014. godine u Silikonskoj dolini s premisom ubrzavanja analitike nad big data sustavima koristeći višejezgrene procesore NVIDIA grafičkih kartica za paralelno izvršavanje upita nad bazom. Cijeli sustav SQream DB baze je napravljen od početka, točnije, nije korišten nijedan postojeći sustav kao temelj za razvoj, npr. Hadoop ili Postgres. Izvršavanje upita na grafičkim procesorima je tehnologija slična sustavima korištenim za „data mining“ kod kriptovaluta, te omogućava masivno paralelno procesiranje podataka na svakoj jezgri procesora grafičke kartice koristeći bržu frekvenciju grafičke memorije od standardne RAM memorije na matičnoj ploči.
U standardnim, često korištenim skladištima podataka (engl. Data Warehouse), sve komponente unutar sustava su usko povezane i zajednički koriste hardverske resurse. Kod velikog protoka podataka i velikog broja korisnika, skaliranje je otežano te se stvaraju problemi s performansama. SQream DB rješava taj problem s inteligentnom internom arhitekturom koristeći odvojeni kompajler, izvršni dio i spremnik podataka, kako bi se bolje optimizirao protok podataka i njihova obrada.
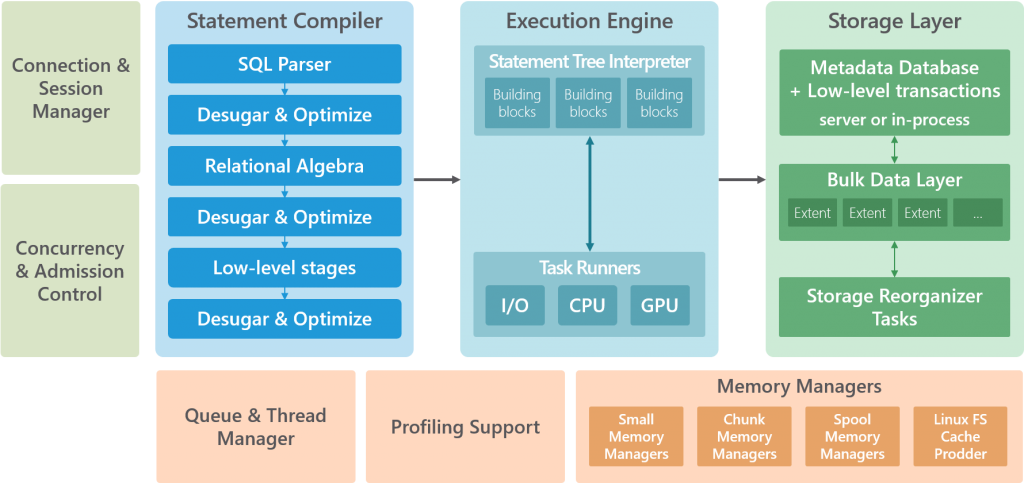
Dva načina particioniranja podataka
Sljedeći korak ubrzanja performansi unutar SQream DB baze postiže se particioniranjem podataka na dva načina, nazvano hiper-particioniranje namijenjeno za što veću kompresiju podataka i njihov protok te se izvršava potpuno automatski.
Prvi dio particioniranja je vertikalni, točnije kolumnarni, koji omogućava selektivni pristup određenim podskupovima kolumni u bazi time smanjujući potrebu za čestim pisanjem/čitanjem s diskova čineći ga savršenim za paraleliziranu obradu podataka, na primjer, preko grafičkog procesora.
Drugi dio particioniranja je horizontalno, točnije, podjela na komade i opsege (engl. chunks and extents). Horizontalna podjela podataka na manje podskupove omogućava bolje iskorištenje hardvera i relativno male količine GRAM-a (RAM na grafičkoj kartici) inteligentnim korištenjem predmemorije (engl. cache) i spajanja podataka (engl. spooling).
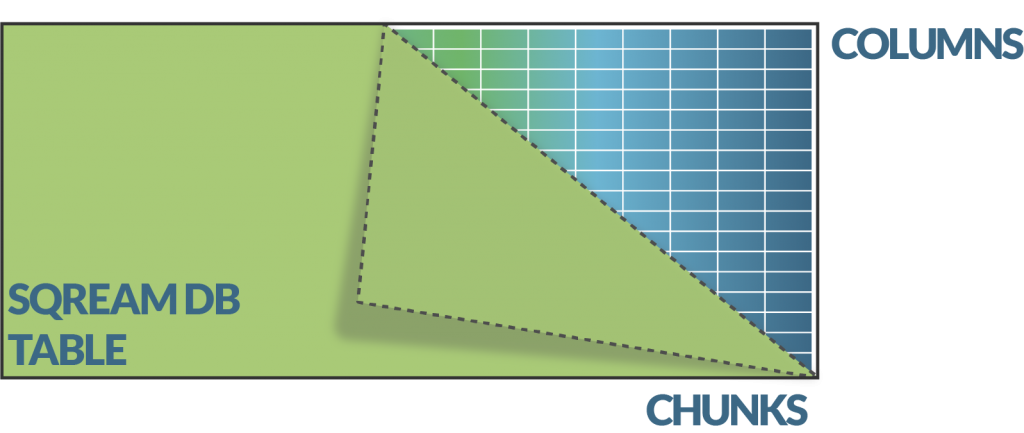
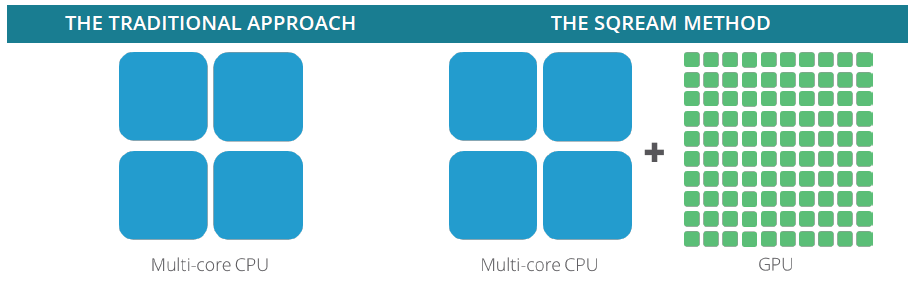
Inteligentno korištenje dostupnih resursa
Standardne data warehouse baze podataka koriste samo procesorske jezgre i RAM memoriju za obradu kod upisivanja i dohvaćanja podataka. Kod SQream DB baze, taj proces je proširen na inteligentno korištenje kombinacije dostupnih resursa procesora, RAM memorije i grafičkih procesora. Na primjer, interni sustav u bazi automatski koristi procesor (CPU), ukoliko bi kopiranje podatka za obradu u grafički procesor (GPU) uzelo previše vremena i usporilo upit/obradu, podižući brzinu ukupnog procesa.
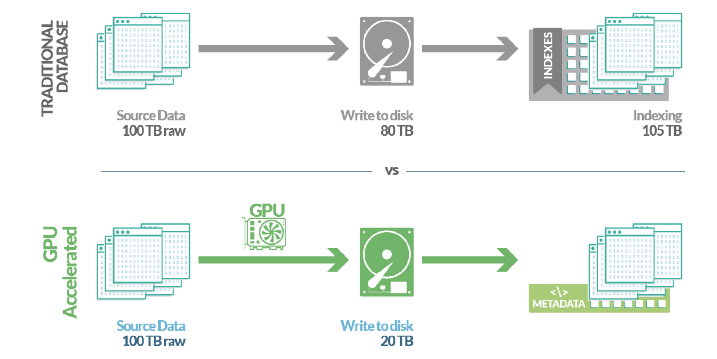
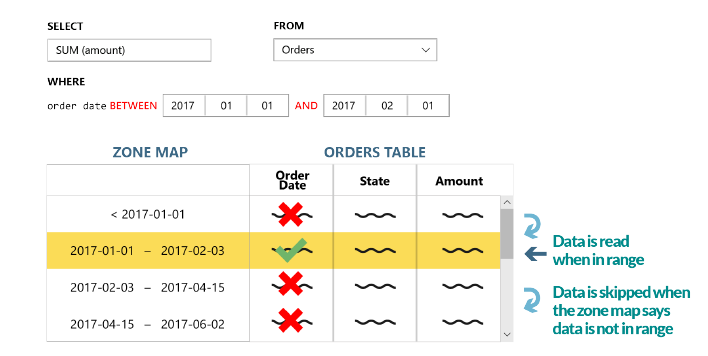
Još jedan revolucionarni pristup spremanju podataka kod SQream DB-a je inteligentno korištenje metadata podataka generiranih obradom preko grafičkih procesora. Metadata podaci sadrže opisne podatke o opsegu (engl. range) i vrijednosti svakog komada (engl. chunks), te su spremljeni zasebno od stvarnih podataka. Time omogućavaju inteligentno preskakanje nepotrebnih opsega podataka kod izvršenih upita tvoreći tzv. zonske mape (engl. zone map) što kao rezultat ima smanjenje korištenja svih hardverskih resursa.
SQream DB sadrži stotine optimizacija i automatizacija dizajniranih da omoguće tvrtkama da se usredotoče na podatke, a ne na upravljanje podacima. Većina baza podataka zahtijeva tim administratora za fino i ručno ugađanje procesa, održavanje indeksiranja, ažuriranje pogleda i projekcija, itd. SQream DB dizajniran je za moderna radna opterećenja koja se često mijenjaju. Napravljen je za rukovanje najgorim mogućim scenarijima i optimiziran je za ogromne skupove podataka, gdje tipične optimizacije baza podataka imaju poteškoća. SQreamovo transparentno prikupljanje metapodataka i prilagodljiva automatska kompresija omogućuju potrošačima podataka pokretanje upita na stotinama terabajta podataka, gdje druge baze podataka jednostavno ne mogu funkcionirati (pokušajte indeksirati skup podataka od 500 TB!).
Laka implementacija SQream baze podataka
SQream DB je potpuno ANSI – 92 SQL kompatibilna i lako se implementira u sve ekosisteme zbog podrške za sve tipične ODBC i JDBC konektore, uključujući i Python, C#, .NET, C++, Java i druge. Nativna podrška za SQL jezik, omogućava korištenje bilo kojeg ETL alata i ostalih aplikacija nad bazom, smanjujući vrijeme implementacije na minimum. Prema mjerenjima iz prakse, količina „ingestanih“ podataka (naravno, u ovisnosti od hardvera) može biti i do 3.5 TB na sat iz raznih izvora, te se može implementirati kao sloj između Apache Kafke i Apache Sparka služeći kao sloj za analitiku između to dvoje.
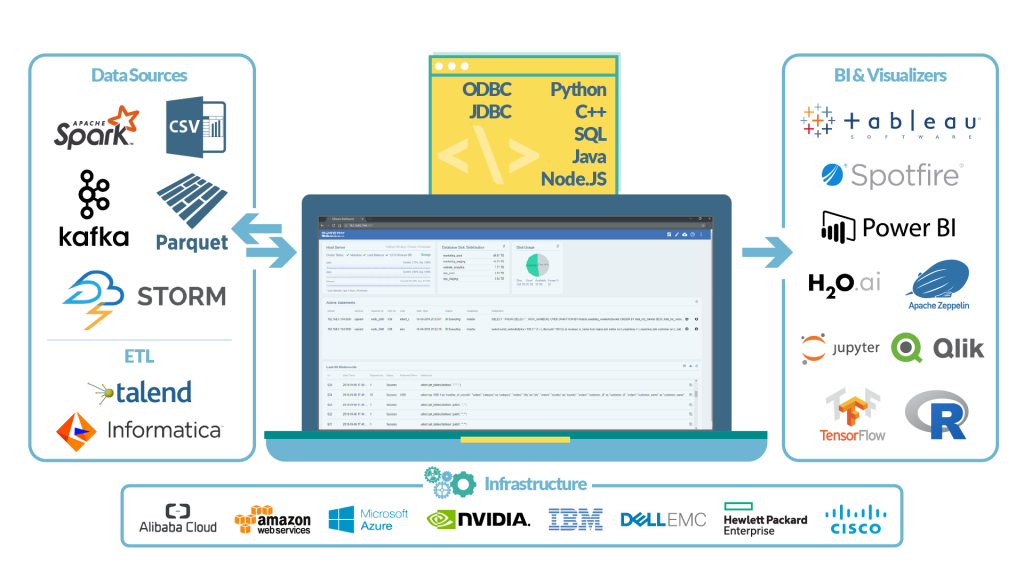
SQream DB ekosustav
SQream DB može raditi na većinu standardnog serverskog x86 – 64 hardvera s Nvidia grafičkim karticama, pa čak i komercijalnim laptopima opremljenim takvim hardverom, no za najbolje performanse se preporučaju 2x Nvidia Tesla grafičke kartice (K80, P40, P100 itd.) te za još veće ubrzanje, IBM POWER9 procesori na kojima se performanse podižu za i do 3.7 puta prema testiranjima.
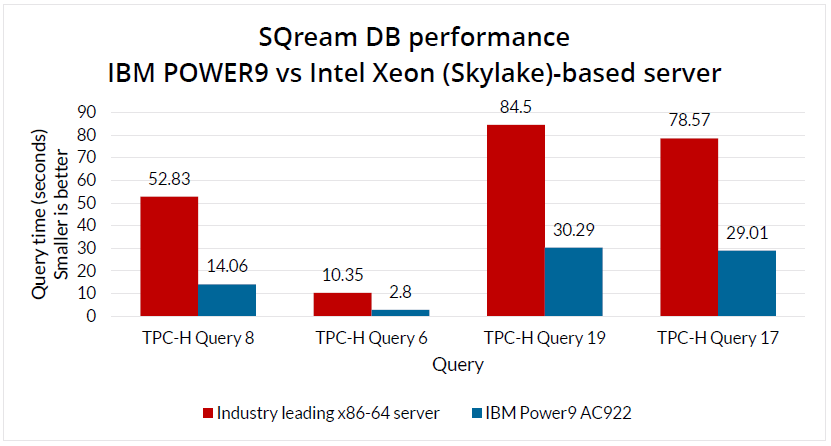
Na nezavisnim testiranjima performansi SQream DB baze, u sustavu mobilnog operatera, pri „ingestu“ od 1.6TB podataka tjedno, performanse pokazuju od 5 – 18 puta veću brzinu uključujući data ingest, kompresiju podataka i brzinu izvršavanja upita, u usporedbi s konkurentskim bazama podataka.
Baza je dostupna u obliku softvera koji možete instalirati na standardnu x86 – 64 ili IBM POWER9 arhitekturu s NVIDIA grafičkim karticama, kao servis u cloudu (Amazon P2 / P3 with NVIDIA Tesla, Azure NCv3 with Tesla V100) i IBM Bluemix bare-metal sustave.
Za sva dodatna pitanja oko SQream baze podataka kontaktirajte nas na tel. +385 1 4091 200 ili na poslovna.rjesenja@megatrend.com.

