Blog ENG
SQream DB – Fastest Time to Insight for Data at Any Scale
SQream is a hybrid analytics platform that gives you the critical insights you need when you need them – on any size of data.

SQream DB is a modern RDBMS database designed for data warehousing of large amounts of data (Big Data) with additional acceleration through graphics processors (GPU). Primarily published in 2014 in Silicon Valley with the premise of accelerating analytics over big data systems using multi-core processors of NVIDIA graphics cards for parallel execution of queries in the database. The entire SQream DB database system was built from scratch, more precisely; no existing system was used as a basis for development, for example, Hadoop or Postgres. Query execution on graphics processors is a technology similar to systems used for “data mining” in cryptocurrencies and enables massively parallel processing of data on each graphics card processor core using a faster graphics memory frequency than the standard RAM memory on the motherboard.
In standard, frequently used data warehouses, all components within the system are closely connected and share hardware resources, and with a large data flow and a large number of users, scaling is difficult and performance problems arise. SQream DB solves this problem with an intelligent internal architecture using a separate compiler, executable, and data container to better optimize data flow and processing.
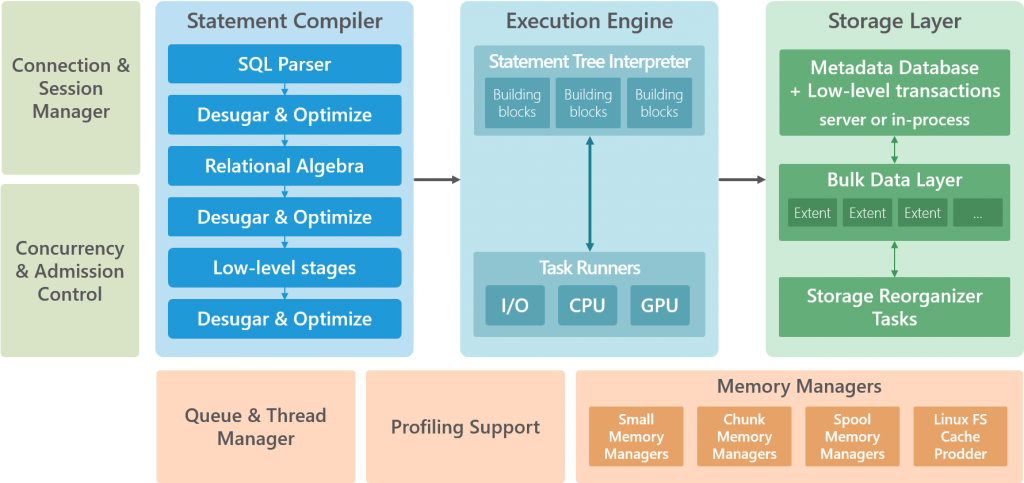
Two methods of data partitioning
The next step of performance acceleration within the SQream DB database is achieved by partitioning data in two ways, called hyper-partitioning intended for the greatest possible compression of data and its flow, and is executed completely automatically.
The first part of the partitioning is vertical, or rather columnar, which enables selective access to certain subsets of columns in the database, thus reducing the need for frequent writing/reading from disks, making it perfect for parallelized data processing, for example, via a graphics processor.
The second part of partitioning is horizontal, more precisely, a division into chunks and extents. The horizontal division of data into smaller subsets enables better utilization of hardware and a relatively small amount of GRAM (RAM on the graphics card) through the intelligent use of cache and data pooling.
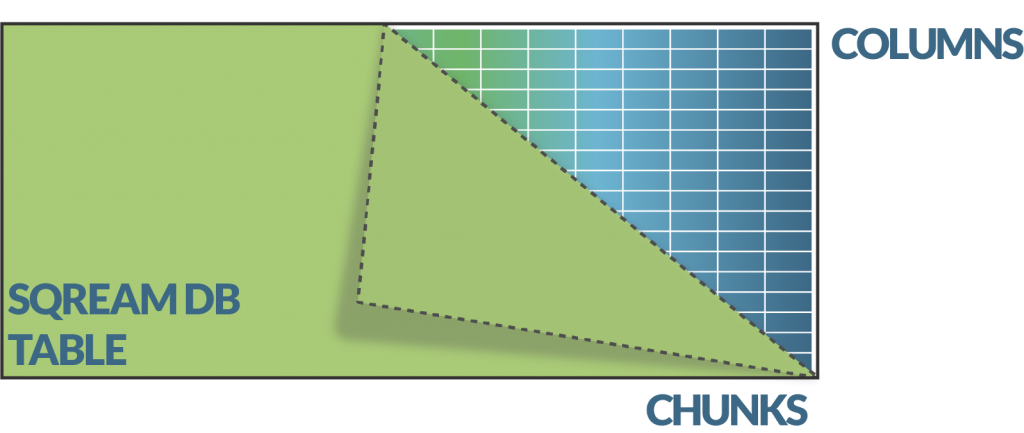
Intelligent use of available resources
Standard data warehouse databases use only processor cores and RAM memory for processing when writing and retrieving data. With the SQream DB database, this process is extended to intelligently use a combination of available resources of the processor, RAM memory, and graphics processors. For example, the internal system in the database automatically uses the processor (CPU) if copying the data for processing to the graphics processor (GPU) would take too much time and slow down the query/processing, increasing the speed of the overall process.
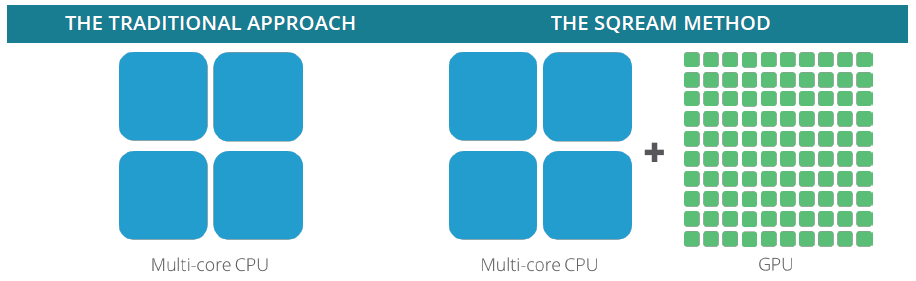
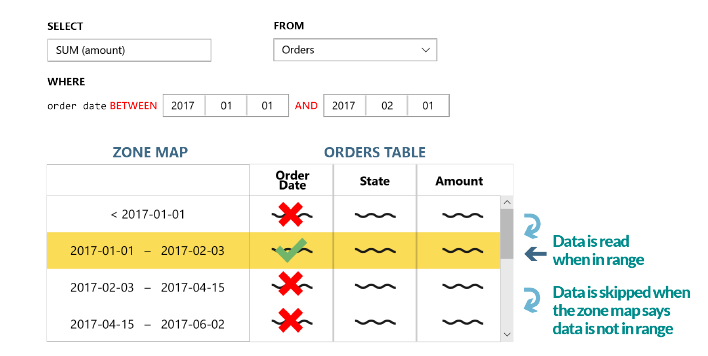
Another revolutionary approach to data storage with SQream DB is the intelligent use of metadata data generated by processing through graphics processors. Metadata data contain descriptive data about the scope (eng. range) and value of each piece (eng. chunks) and are saved separately from the real data, thus enabling intelligent skipping of unnecessary data ranges during executed queries, forming the so-called zone map, which results in a reduction in the use of all hardware resources.
SQream DB features hundreds of optimizations and automation designed to enable businesses to focus on data, not data management. Most databases require a team of administrators to fine-tune and manually process processes, maintain indexing, update views and projections, etc. SQream DB is designed for modern, frequently changing workloads. It is built to handle worst-case scenarios and is optimized for huge data sets, where typical database optimizations struggle. SQream’s transparent metadata collection and adaptive automatic compression, enable data consumers to run queries on hundreds of terabytes of data, where other databases simply cannot function (try indexing a 500 TB dataset!).
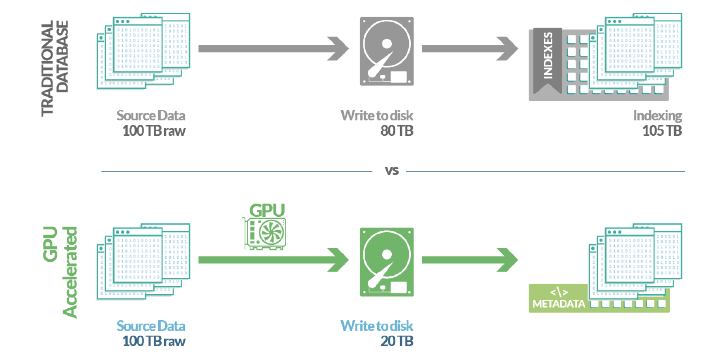
Deployment of the SQream DB
SQream DB is fully ANSI – 92 SQL compliant and easily deployed in all ecosystems due to support for all typical ODBC and JDBC connectors, including Python, C#, .NET, C++, Java, and others. Native support for the SQL language enables the use of any ETL tool and other applications over the database, reducing the implementation time to a minimum. According to measurements from practice, the amount of “ingested” data (of course, depending on the hardware) can be up to 3.5 TB per hour from various sources, and it can be implemented as a layer between Apache Kafka and Apache Spark serving as a layer for analytics between those two.
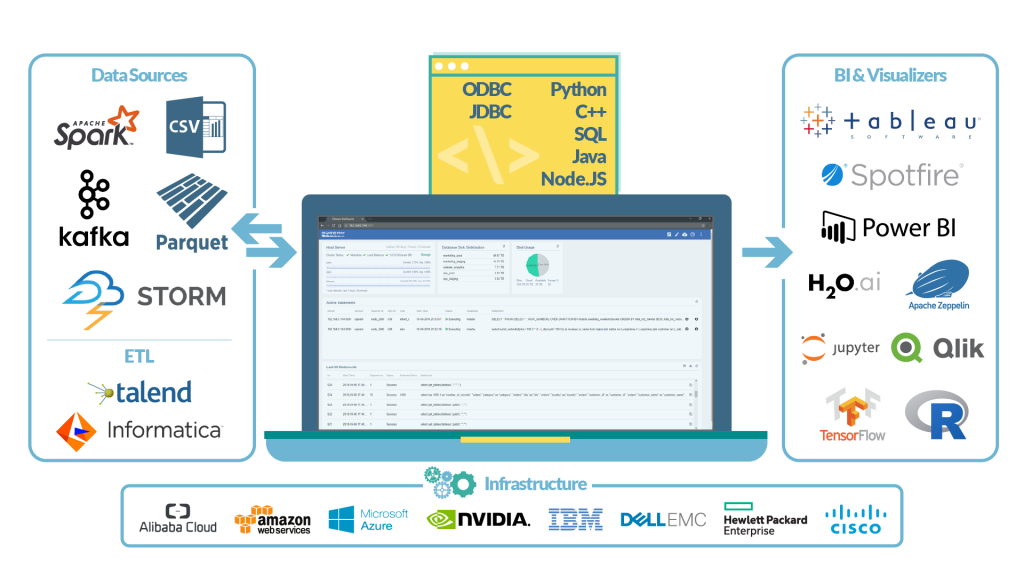
SQream DB ecosystem
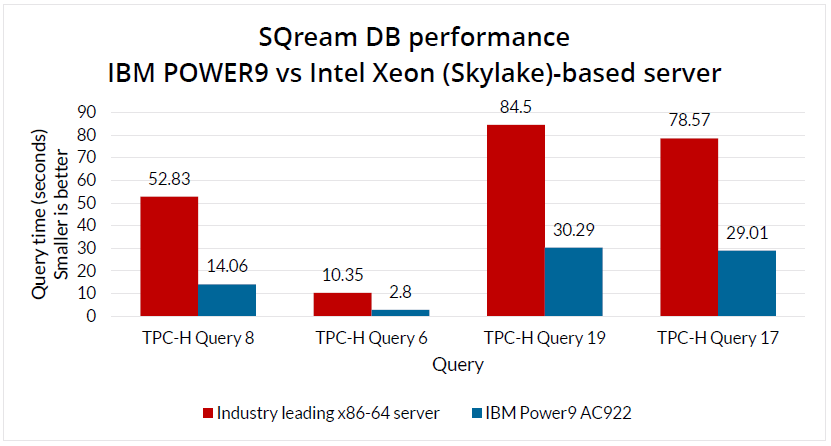
SQream DB can run on most standard server x86 – 64 hardware with Nvidia graphics cards, and even commercial laptops equipped with such hardware, but for best performance 2x Nvidia Tesla graphics cards (K80, P40, P100, etc.) are recommended. For even larger acceleration, IBM POWER9 processors on which performance increases by up to 3.7 times according to tests. In independent performance tests of the SQreamDB database, in the system of a mobile operator, with an “ingest-in” of 1.6TB of data per week, the performance compared to competing databases shows 5-18 times higher speed including data ingest, data compression and query execution speed.
The database is available in the form of software that you can install on standard x86-64 or IBM POWER9 architecture with NVIDIA graphics cards, as a service in the cloud (Amazon P2 / P3 with NVIDIA Tesla, Azure NCv3 with Tesla V100) and IBM Bluemix bare-metal systems.
For more questions about the SQream DB, contact us at +385 1 4091 200 or poslovna.rjesenja@megatrend.com.

