Blog
Automatizacija web preglednika – Selenium WebDriver
Što je Selenium?
Selenium je skupina open source alata i biblioteka koje su usmjerene na automatizaciju operacija unutar web preglednika, bilo da se radi o testiranju web aplikacija, automatiziranom pregledavanju weba i preuzimanju sadržaja (web scraping) ili automatizaciji nekih operacija za koje je neefikasno i nepotrebno da ih uvijek rade ljudski korisnici.
Selenium WebDriver jedan je takav alat, pomoću kojeg je moguće napisati slijed instrukcija koji upravlja ponašanjem web preglednika, neovisno o vrsti web preglednika. Trenutno su dostupni driveri za sve popularne web preglednike – Chromium/Chrome, Firefox, Edge, Internet Explorer, Safari (integrirani driver) i Opera.
Demonstracija rada
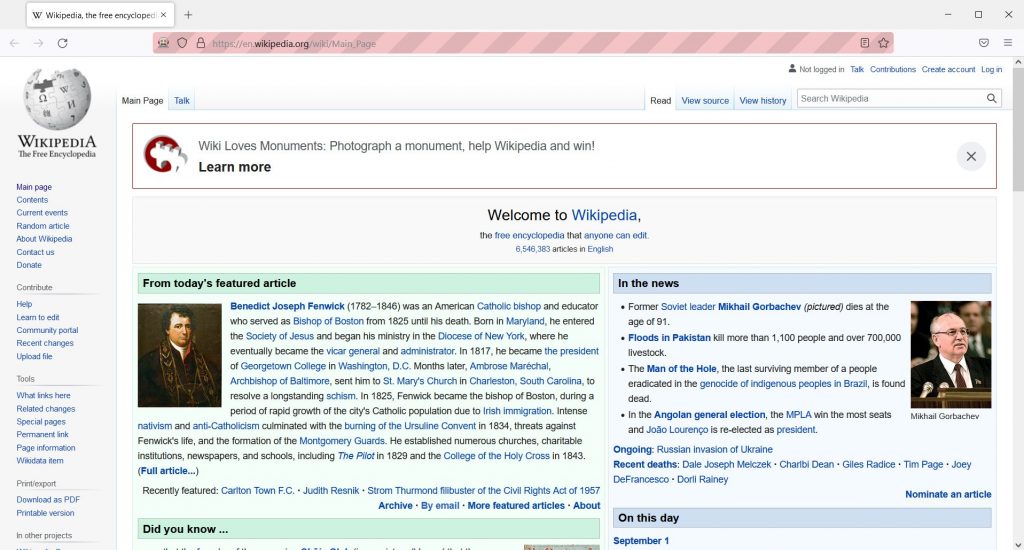
U ovom blogu demonstrirat ćemo kako izraditi jednu takvu Selenium skriptu u programskom jeziku Python za zadatak preuzimanja sadržaja s web stranica (hibrid automatizacije zadataka i web scrapinga).
Naša skripta će ući na stranicu engleske Wikipedije, unijeti željeni pojam, ući na odgovarajuću stranicu vezanu za taj pojam te na njoj redom kliknuti na sve poveznice unutar wiki članka i preuzeti sve te wiki članke u obliku PDF datoteke klikom na gumb “Download as PDF”.
Preduvjeti
Za početak moramo odabrati web preglednik koji ćemo koristiti za našu skriptu, odnosno koji ćemo automatizirati. Nakon toga trebamo preuzeti odgovarajući službeni driver za web preglednik. Poveznice za preuzimanje svih drivera možete pronaći na poveznici [https://selenium-python.readthedocs.io/installation.html#drivers]. Za potrebe ovog bloga koristit ćemo preglednik Mozilla Firefox, odnosno Geckodriver. Nakon preuzimanja drivera izvršnu datoteku potrebno je smjestiti u vršni direktorij instalacije Pythona (npr. C:/Users/[korisnik]/AppData/Local/Programs/Python/Python37-32) ili ga smjestiti u PATH sustava.
Za rad u Pythonu naravno prvo je potrebno imati instaliran Python, a u njemu ćemo dodatno instalirati modul “selenium” (Python binding) pomoću naredbe “pip install selenium”. Otvaramo novu Python skriptu i spremni smo za rad.
Skripta
Na početku je potrebno uvesti sve potrebne module koje ćemo koristiti u skripti, konkretno ovdje koristimo samo dva modula, već navedeni “selenium” koji smo instalirali iz PyPI-ja te u distribuciju Pythona integrirani modul “time”, koji ćemo koristiti za vremenske stanke.

Prije nego što krenemo davati naredbe WebDriveru poželjno je definirati ponašanje preglednika pri preuzimanju datoteka s web stranica. Ako podrazumijevamo određeno ponašanje, često ćemo naići na probleme. Modifikaciju defaultnog ponašanja možemo ostvariti kreiranjem Firefox profila, gdje definiramo da se PDF datoteke spremaju direktno u specificirani direktorij te onemogućimo otvaranje PDF pretpregleda unutar preglednika.

Prije glavnog dijela upravljanja preglednikom još ćemo definirati naše osnovne parametre, duljinu stanki, URL adresu sjedišta (početna adresa) i upit. Želimo li recimo pretraživati neku drugu Wikipediju (drugi jezik), trebamo promijeniti varijablu url.

Inicijaliziramo WebDriver koristeći specificirani Firefox profil kao argument, koristeći GET metodu (HTTP) dolazimo do specificirane stranice (engleske Wikipedije) te uvećavamo prozor na veličinu cijelog ekrana.
Nakon toga koristimo sleep() metodu modula time, kako bismo proveli vremensku stanku specificirane duljine (varijabla delay). To radimo kako bismo osigurali da će se cijela stranica učitati do kraja. WebDriver po defaultu čeka s izvođenjem sljedećeg dijela koda dok se statički dio stranice ne učita, ali ne može znati kada je gotovo učitavanje dinamičkog sadržaja (JavaScript). Ovo je naravno primitivniji način zaštite od traženja elemenata koji se još nisu učitali, pa alternativno možemo koristiti pomoćnu WebDriver metodu WebDriverWait, kod koje možemo specificirati da WebDriver čeka dok se određeni element ne pojavi na stranici. Za potrebe ovog bloga ići ćemo na time.sleep() opciju radi jednostavnosti.

Ovdje prvi put dolazimo do zadatka pronalaska određenog elementa na stranici. U sklopu ovog bloga nećemo ići u detalje, pošto je sve odlično opisano u službenoj dokumentaciji [https://selenium-python.readthedocs.io/locating-elements.html], ali ćemo spomenuti osnovne načine kako locirati element unutar web stranice:
- id ili class elementa (id je atribut koji služi kao jedinstveni identifikator nekog elementa, dok više elemenata može imati jednaki class)
- name atribut
- XPath ili CSS selektori
- ime HTML oznake
- tekst poveznice (potpuni ili parcijalni)
U našem slučaju prvo trebamo pronaći polje za unos teksta (tražilicu). Njezin id ćemo pronaći standardnom metodom inspekcije web stranice (Inspect element, F12). Kada smo locirali element, možemo započeti interakciju s njim, konkretno ovdje u to polje trebamo unijeti naš tekstualni upit (specificiran u varijabli query) i simulirati pritisak tipke Enter (Return). Time dolazimo na stranicu rezultata tražilice.

Ovdje možemo najjednostavnije doći do istoimenog wiki članka tako što ćemo pronaći poveznicu koja ima prikazni tekst jednak našem upitu. Kada lociramo tu poveznicu, simuliramo klik mišem, što nas dovodi do prvog wiki članka.

Kada smo došli do glavnog wiki članka, krećemo u pronalaženje i iteriranje kroz sve poveznice unutar sadržaja članka. Na početku definiramo što URL adrese tih poveznica moraju i što ne smiju sadržavati (direktno filtriranje beskorisnih poveznica). Poveznice ćemo pronaći pretraživanjem svih HTML oznaka s imenom “a”. Iz tih oznaka uzimamo samo atribut “href”, koji sadrži URL adresu poveznice.

Definiramo tekst poveznice koja vodi na stranicu za preuzimanje PDF datoteke članka (ovisno o jeziku). Na glavnom wiki članku pronalazimo poveznicu i kada se stranica učita simuliramo klik na gumb za preuzimanje, čime smo preuzeli prvu PDF datoteku.

Sada isto radimo za svaku poveznicu koju smo prikupili unutar glavnog wiki članka. Iteriramo kroz listu poveznica, za svaku radimo GET zahtjev, tražimo poveznicu za preuzimanje PDF datoteke i preuzimamo PDF klikom na gumb. U slučaju da nešto pođe po krivu (poveznica ili gumb se ne učitaju), ovaj dio koda stavili smo unutar try-except bloka. Na kraju zatvaramo WebDriver pomoću metode .close().

Zaključak
Kroz demonstraciju unutar ovog bloga pokazali smo koliko je jednostavno napisati skriptu za automatizaciju web preglednika u razne svrhe, bilo da trebamo preuzeti neki sadržaj s weba, automatizirati neki zadatak ili testirati ponašanje web aplikacije u pregledniku. O kojem god da se području radi, Selenium WebDriver je alat koji je odlično imati spreman za ovakve zadatke. Ako želite saznati više o alatu Selenium WebDriver, web scrapingu ili funkcioniranju koda ove demonstracije, slobodno se javite autoru ovog bloga na domagoj.maric@megatrend.com.

