Blog
Crash course regularnih izraza
Regularni izrazi (engl. Regular Expressions, RegEx) su sekvence znakova koje opisuju skup sekvenci znakova (engl. search pattern) prema određenim sintaksnim pravilima. Korisni su za pronalaženje specifične informacije unutar veće količine tekstualnih podataka.
Regularni izrazi imaju široko područje primjene:
- tražilice, algoritmi za pretragu stringova (find, find and replace sustavi),
- predobrada tekstualnih podataka, čišćenje podataka,
- validacija (ulaznih) podataka, npr. validacija lozinki,
- automatizirano pretraživanje web prostora (engl. web scraping), npr. pronalaženje svih URL adresa ili e-mail adresa na određenoj web stranici,
- virtualni asistenti – usmjeravanje dijaloga u slučaju prepoznavanja određenih uzoraka, npr. prikupljanje kontakt broja telefona od sugovornika/korisnika.
Prednosti i nedostaci korištenja
Prednosti:
- vrlo moćan alat za obradu tekstualnih podataka,
- brz razvoj uz dovoljne vještine,
- jednostavnost uporabe u većini programskih jezika i alata,
- široka podrška za regularne izraze – praktički ne postoji programski jezik u kojem nije moguće koristiti regularne izraze (često kroz standardne ugrađene biblioteke).
Nedostatci:
- loša čitljivost,
- “steep learning curve” – vrijeme potrebno da se regex napiše,
- vrijeme potrebno da se regex napiše točno (često postoji velika količina posebnih slučajeva),
- jedan šaljivi citat (Jamie Zawinski): “Neki ljudi kada naiđu na problem pomisle “Znam, mogao bih koristiti regularne izraze”. Sada imaju dva problema.”
- često postoji bolji alat za rješenje problema (rijetko će u real-world problemima biti potrebno i prikladno riješiti ih isključivo regexima, ali je bitno znati kako kombinirati regularne izraze i druge tehnike obrade teksta na ispravan način).
Pregled najbitnijih koncepata
Vrste znakova
Dvije su vrste znakova u regularnim izrazima. Prva vrsta su standardni, doslovni znakovi, koji predstavljaju sami sebe. Primjerice, regex konstruiran samo od standardnih znakova predstavljat će uzorak za doslovni match u tekstu, regex “primjer” će matchati samo pojave tih 7 znakova u tekstu u kojem tražimo (čak i u slučaju riječi “primjerima”, “primjerice”…).
Druga vrsta su metaznakovi, posebni znakovi. Oni imaju posebna značenja, ovisno o kontekstu i sintaktičkim pravilima, a bit će opisani kroz sljedeća potpoglavlja. Ako metaznaku prethodi znak unazadne kose crte (engl. backslash, “\”), on postaje doslovni znak. Primjerice, točka je metaznak, ali ako želimo matchati znak točke u tekstu, onda ćemo to u regexu označiti kao “\.”.
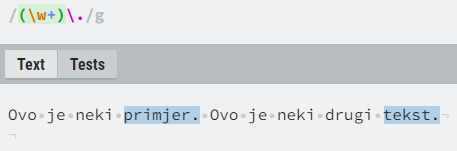
označili sve zadnje riječi u rečenici
(one iza kojih se nalazi točka, koja naravno nije jedini
interpunkcijski znak)
Vertikalna linija i zagrade
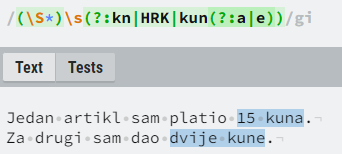
Vertikalna linija u regexu odvaja alternative. Ona zapravo služi kao logička operacija ILI između dva ili više stringova. Primjerice, regex “krumpir|krompir” predstavlja sekvence znakova “krumpir” ili “krompir”.
Oble zagrade dodatno se koriste kako bi se definirao opseg i poredak operatora poput vertikalne linije. Primjerice, zadnji navedeni regex možemo napisati i kao “kr(u|o)mpir”, čime uveliko štedimo u broju znakova i povećavamo čitljivost. Oble zagrade mogu se koristiti i kao capturing grupe, što je objašnjeno kasnije u zasebnom potpoglavlju.
Uglate zagrade koriste se kao alternativa toj kombinaciji vertikalne linije i oble zagrade, na bazi jednog znaka. Isti regex možemo napisati pomoću uglatih zagrada i kao “kr[ou]mpir”. Na jednak način možemo i ručno definirati skupine, odnosno raspone znakova za koje želimo da se pojavljuju, odnosno ne pojavljuju, koristeći pri tome znak crtice za definiciju raspona, a znak kućice (“^”) za negaciju. Primjerice, “[a-z]” označava sva mala slova (engleske abecede), “[A-Z]” sva velika slova, “[^0-9]” sve osim brojeva/znamenki itd.
Kvantifikatori
Kvantifikator poslije znaka ili grupe znakova specificira koliko često se prethodni element smije pojaviti.
Znak upitnika (“?”) označava nijedno ili jedno pojavljivanje prethodnog elementa. Primjerice, regex “zadat?ci” predstavlja stringove “zadaci” i “zadatci”.
Zvjezdica (asterisk, “*”) označava nula ili više pojava prethodnog elementa. Primjerice, regex “ab*c” predstavlja stringove “ac”, “abc”, “abbc”, “abbbc” itd.
Plus znak (“+”) označava jednu ili više pojava prethodnog elementa. Funkcionira jednako kao zvjezdica, ali eliminira mogućnost nepojavljivanja prethodnog elementa. Primjerice, regex “ab+c” predstavlja stringove “abc”, “abbc”, “abbbc”, “abbbbc” itd.
Želimo li specificirati točan broj ili raspon brojeva pojava prethodnog elementa, možemo koristiti vitičaste zagrade:
- {n} – prethodni element pojavljuje se točno n puta,
- {min,} – prethodni element pojavljuje se najmanje min puta,
- {min,max} – prethodni element pojavljuje se najmanje min puta, ali ne više od max puta.
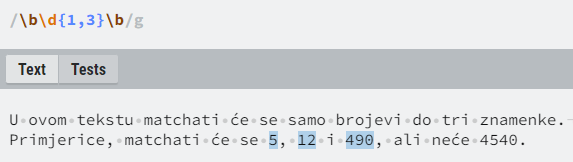
Wildcard
Zamjenski znak (engl. wildcard), znak točke, predstavlja bilo koji znak.
Primjeri:
- “a.b” predstavlja bilo koji string koji se sastoji od početnog znaka “a”, završnog znaka “b”, s bilo kojim znakom između njih (“a b”, “aab”, “abb”, “azb”, “aKb”, “a4b”…),
- “a.*b” predstavlja bilo koji string koji počinje znakom “a”, te sadrži znak “b” na kraju, s proizvoljnim brojem znakova između (“a1eb”, “abc b”, “ab”…).
Grupe znakova
U sintaksi regularnih izraza postoje i predefinirane grupe znakova, koje su nam korisne kako ne bismo morali manualno definirati skupove znakova uglatim zagradama. Primjerice, ako želimo definirati sve alfanumeričke znakove, umjesto dugačke definicije uglatim zagradama “[a-zA-Z0-9_]” možemo koristiti grupu znakova “\w”. Ako želimo definirati sve osim alfanumeričkih znakova, onda jednostavno pretvorimo izraz grupe znakova u veliko slovo – “\W”.
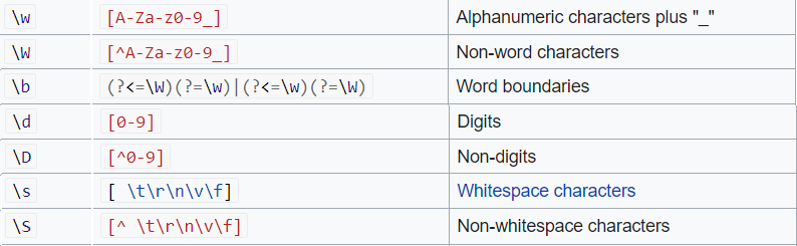
Pored osnovnih grupa znakova (alfanumerički, brojke, whitespace znakovi) bitno je spomenuti i “\b”, koji označava granice između riječi (engl. word boundaries).
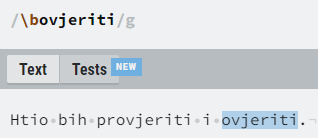
grupe znakova
Lazy matching
Osnovni kvantifikatori u regularnim izrazima po defaultu su pohlepni (engl. greedy), tj. pokušavaju označiti što je više moguće znakova. Takvo ponašanje moguće je modificirati dodavanjem znaka upitnika (“?”) poslije kvantifikatora, kako bi se označavalo što manje znakova.
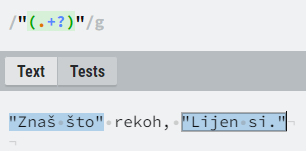
lazy operatora (probajte ukloniti upitnik)
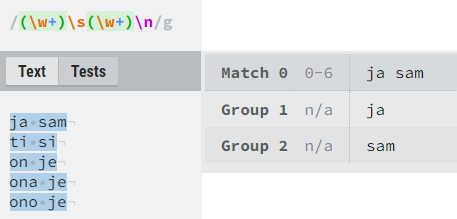
Capturing grupe i unazadno referenciranje
Capturing grupe su korisne u regexima iz više razloga. Primarno se koriste kako bi se rezultati pretrage pomoću regexa mogli lakše iskoristiti. Njih u regexima ostvarujemo pomoću oblih zagrada, a ako negdje želimo koristiti grupiranje pomoću oblih zagrada te nam nije važna informacija koja će biti uhvaćena, možemo capturing grupu pretvoriti u non-capturing grupu pomoću znakova “?:” poslije lijeve zagrade. Primjerice, ako imamo regex “([A-Z])(\d)(?:AB|CD)”, prve dvije grupe ćemo dobiti odvojene, a treću odbacujemo.
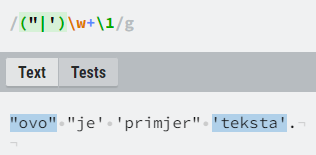
Druga korisna značajka capturing grupa je njihovo unazadno referenciranje (engl. backreferencing). Unutar regexa pomoću “\1”, “\2” itd. se možemo referencirati na prošle definirane capturing grupe. Njih primjerice možemo koristiti kako bismo osigurali slaganje vrsta navodnika (navodnik koji dolazi na kraju mora biti jednak onome što je uhvaćeno na početku), kako je prikazano u primjeru na slici 8.
Početak i kraj stringa
U regularnim izrazima postoje i posebne oznake za početak i kraj stringa, znak kućice “^”, odnosno dolara “$”. Oni su korisni ako želimo specificirati da se neka sekvenca znakova mora pojavljivati na početku, odnosno kraju stringa koji pretražujemo, ili da string koji pretražujemo ne smije imati ništa dodatno osim uzorka koji smo specificirali (da njemu odgovara od vlastitog početka do kraja).
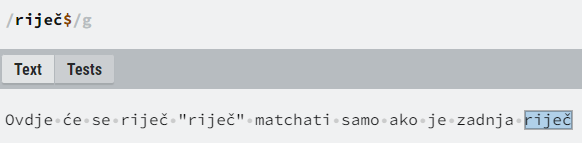
Lookarounds
Vjerojatno najkompliciraniji aspekt regularnih izraza su tzv. lookarounds. Oni osiguravaju da se neki zadani uzorak nalazi prije (lookbehind), odnosno poslije (lookahead) određenog mjesta u regexu, bez da se regex engine pomakne unutar stringa. Lookarounds se dijele na dvije vrste prema smjeru (lijevo ili desno od određene točke) i prema predznaku (hoće li se osiguravati da se određeni uzorak pojavljuje ili ne pojavljuje). Primjerice, ako želimo osigurati da se određeni uzorak ne smije pojavljivati prije određenog mjesta u regexu, pričamo o negativnom lookbehindu.
| Predznak\Lookaround(smjer) | Lookbehind | Lookahead |
| Pozitivni | (?<=uzorak) | (?=uzorak) |
| Negativni | (?<!uzorak) | (?!uzorak) |
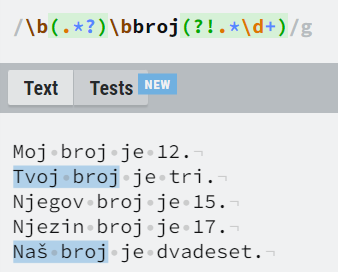
(poslije riječi “broj” se ne smije pojaviti broj u numeričkom obliku)
Najpopularnije područje primjene lookaroundova je validacija tekstualnih podataka, najčešće korisničkih lozinki. Primjerice, pomoću pozitivnog lookaheada možemo odrediti da lozinka mora sadržavati barem jedno malo slovo, jedno veliko slovo, jednu znamenku, jedan specijalni znak i biti ukupne duljine barem 8 znakova (pomoću kvantifikatora, vitičaste zagrade). Dodatno, možemo postaviti i negativni lookahead, recimo da lozinka ne smije sadržavati određene izraze poput “password”, datume rođenja i sl.

Zastavice
Valja napomenuti da je u radu s regularnim izrazima moguće postaviti i vrijednost raznih zastavica, koje modificiraju ponašanje pretrage. Najbitnija zastavica je vjerojatno “i”, koja označava tzv. case insensitive search, pretragu koja ignorira različitost velikih i malih slova.

Praktični primjeri
Nekoliko praktičnih primjera regularnih izraza za ekstrakciju specifičnih informacija:
- jednostavni uzorak za e-mail adrese,
- ^\w+@[a-zA-Z_]+?\.[a-zA-Z]{2,3}$
- MAC adrese,
- ^([0-9A-Fa-f]{2}[:-]){5}([0-9A-Fa-f]{2})$
- IP adrese.
- ^(?:[0-9]{1,3}\.){3}[0-9]{1,3}$
- ^(?:(?:25[0-5]|2[0-4][0-9]|[01]?[0-9][0-9]?)\.){3}(?:25[0-5]|2[0-4][0-9]|[01]?[0-9][0-9]?)$
Zaključak
Svi primjeri unutar ovog blog posta vizualizirani su pomoću online alata za testiranje regularnih izraza – RegExr (regexr.com), koji i preporučamo za bilo kakvo učenje, testiranje i eksperimentiranje s regularnim izrazima.
Regularni izrazi pokazali su se kroz prošlost kao odličan alat za obradu tekstualnih podataka, bilo da se radi o olakšavanju pretraživanja veće količine teksta u datotekama, pretraživanju web stranica, radu s bazama podataka ili implementaciji sustava za validaciju. Vjerujemo da će vam ovaj crash course regularnih izraza dati solidne vještine za početak njihove primjene.
Ako imate bilo kakvih pitanja oko korištenja regularnih izraza, ili pak trebate pomoć u konstrukciji onog pravog regexa koji će pokriti sve željene slučajeve (i ignorirati neželjene), slobodno se javite autoru na domagoj.maric@megatrend.com.

