Blog ENG
Regex crash course
Regular expressions are character sequences which represent a set of character sequences (strings, search patterns) according to certain syntax rules. They are useful for finding specific information within a larger quantity of text data.
Regular expressions have many applications:
- search engines, string search algorithms (find, find and replace systems),
- preprocessing of text data, data cleaning,
- (input) data validation, e.g. password validation,
- automated web search/browsing, web scraping, e.g. finding all URL addresses or e-mail addresses on a certain web page,
- virtual assistants – guiding a dialog in case of detection of certain patterns, e.g. collecting contact phone numbers from the user.
Pros and cons of using regular expressions
Pros:
- a very powerful tool for processing text data,
- fast development with adequate skills,
- simple usage in most programming languages and tools,
- broad support for regular expressions – there is practically no programming language in which you can’t utilize regular expressions (usually implemented through standard module libraries).
Cons:
- poor readability,
- “steep learning curve” – time required to write a regex,
- time required to write a regex correctly (it’s often the case of many special cases),
- one humorous joke (by Jamie Zawinski): “Some people, when confronted with a problem, think ‘I know, I could use regular expressions’, now they have two problems”.
- there is often a more suitable tool for solving the problem (it is rarely the case in real world problems that you should solve it using just regular expressions, but you should know how to combine regular expressions with other techniques in a correct way).
Overview of the most important concepts
Character types
There are two types of characters in regexes. The first type are standard, literal characters, which represent themselves. For example, a regex constructed from exclusively literal characters would represent a pattern for literal matching within a text, regex “example” will only match an occurrence of these 7 characters in the target text (it will also match the first 7 characters in “examples”).
The second type are metacharacters, special characters. They have special meaning depending on the context and syntax rules, and will be described in detail in several next subchapters. If a metacharacter is preceded by a backslash (“\”), it becomes a literal character, e.g. a dot is a metacharacter, and if we want to match a literal dot character in a text, we will use a regex with “\.”.
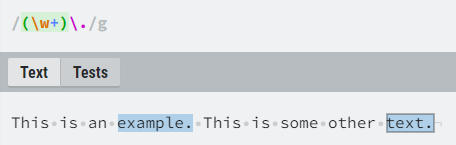
into a literal character, so we can match all last words in the sentences
(those that end with a dot, which is of course not the only
character to end a sentence with).
Vertical line and brackets
The vertical line separates alternatives in regular expressions. It is in a nutshell a logical OR operation between two or more strings. For example, the regex “organize|organise” represents the character sequences “organize” and “organize”.
Round brackets are additionally used so we can define a scope and order of operators like the vertical line. For example, the last regex can also be written as “organi(s|z)e”, which reduces the regex size significantly and boosts readability. Round brackets can also be used as capturing groups, which will be explained in a separate subchapter.
Square brackets can also be used as an alternative to the vertical line + round brackets combination, on a 1 character level. Thus the last regex can also be written as “organi[sz]e”. In the same way we can manually define character groups and intervals which we want to occur (or not to occur), using square brackets, hyphens (“–“) and hat symbols (“^”). For example, “[a-z]” matches all lowercase letters (English alphabet), “[A-Z]” all uppercase letters, “[^0-9]” all characters except numbers/digits etc.
Quantifiers
A quantifier after a character or character group specifies how many times the preceding element can occur.
The question mark (“?”) indicates zero or one occurrences of the preceding element, e.g. ”colou?r” represents the strings “color” and “colour”.
The asterisk sign (“*”) indicates zero or more occurrences of the preceding element, e.g. “ab*c” represents the strings “ac”, “abc”, “abbc”, “abbbc” etc.
The plus sign (“+”) indicates one or more occurrences of the preceding element. It works similarly to the asterisk, but eliminates the possibility of no occurrence of the preceding element. For example the regex “ab+c” represents the strings “abc”, “abbc”, “abbbc”, “abbbbc” etc.
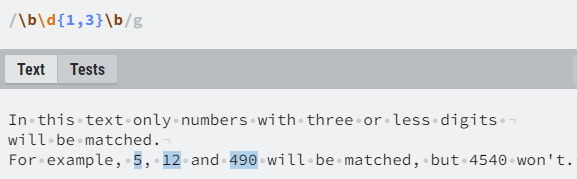
Should we want to specify a specific number or range of occurrences of the preceding element, we could use curly brackets:
- {n} – the preceding element occurs exactly n times,
- {min,} – the preceding element occurs not less than min times,
- {min,max} – the preceding element occurs at least min times, but not more than max times.
Wildcard
The wildcard character, the dot, matches any character.
Examples:
- “a.b” represents any string which starts with an “a”, ends with a “b”, with any character between them (“a b”, “aab”, “abb”, “azb”, “aKb”, “a4b”…),
- “a.*b” represents any string which starts with an “a”, ends with a “b”, with any number of arbitrary characters between them (“a1eb”, “abc b”, “ab”…).
Characters groups
In the syntax of regular expressions there also exist some predefined character groups, which are useful so we don’t have to manually define character groups using square brackets. For example, if we want to define all alphanumeric characters, instead of the long square brackets definition “[a-zA-Z0-9_]” we can use the character group “\w”. If we want to define all but alphanumeric characters, we just use the uppercase version – “\W”.
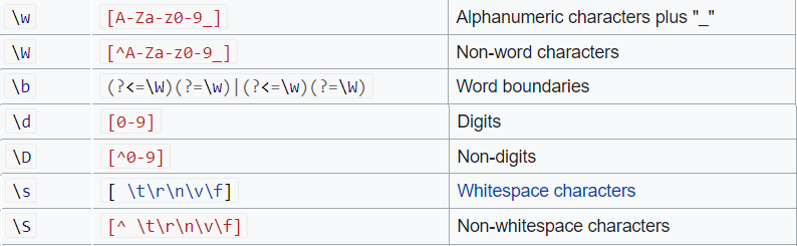
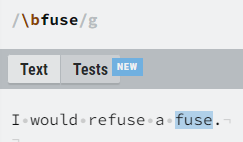
Aside from the basic character groups (alphanumeric, digits, whitespace), we should also mention “\b”, which represent word boundaries.
Lazy matching
The basic regex quantifiers are by default greedy, i.e. they try to match as many characters as possible. Such a behavior can be modified by adding a question mark (“?”) after the quantifier, so as few as possible characters would be matched.
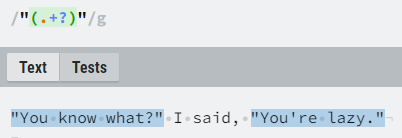
lazy operator (try removing the question mark and
see what happens)
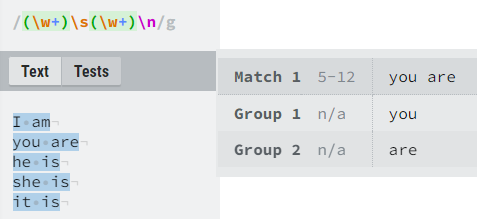
Capturing groups and backreferencing
Capturing groups are useful in regexes in multiple ways. They are primarily used so that the results of a regex search can be used easier. They are implemented in regexes by using round brackets, and if we want to just use grouping, but don’t need the information what would be captured, we can turn the capturing group into a non-capturing group via the two characters “?:” after the left bracket. For example, if we have a regex “([A-Z])(\d)(?:AB|CD)”, the first two groups will return two separated values, while the third will be discarded.
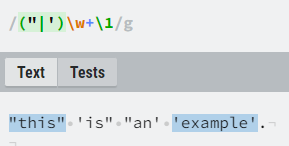
The second useful feature of capturing groups is their backreferencing. By using “\1”, “\2” etc. within regexes we can reference previously captured groups. For example, we can use backreferenced groups so we assert that two quotation marks are matched (the starting quotation mark must match the ending one), as seen in image 8.
Start and end of string
In regular expressions there are special labels for the beginning and the end of a string, the hat sign “^” and the dollar sign “$”, respectively. They are useful when we want to specify that a certain character sequence occurs at the beginning or at the end of a string we are searching in, or when we want that the string has nothing else except our specified pattern (it is matched to the pattern from beginning to end).
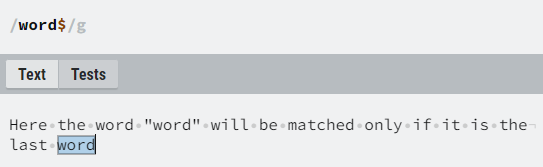
Lookarounds
Lookarounds are probably the most complex concept in regular expressions. They assert that a certain pattern occurs before (lookbehind) or after (lookahead) a set position in the regex, without the regex engine moving within the string. Lookarounds have 4 total different versions, there are two types when talking about the direction (left or right from a position), and two types depending on the sign (assertion that the pattern must or must not occur). For example, if we want to assert that a set pattern must not occur before a set position in the regex, we are talking about a negative lookbehind.
| Sign\Lookaround(direction) | Lookbehind | Lookahead |
| Positive | (?<=patten) | (?=pattern) |
| Negative | (?<!pattern) | (?!pattern) |
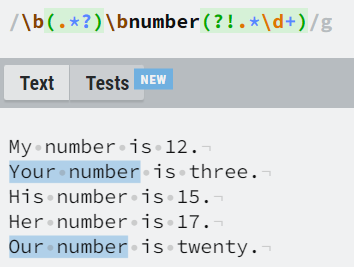
(after the word “number” a number in numeric format
must not occur)
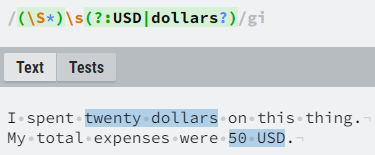
The most popular application of lookarounds is the validation of text data, most commonly user passwords. For example, by using positive lookaheads we can assert that the password must have at least one lowercase character, one uppercase character, one digit, one special character and have a total length of 8 or more characters (via custom quantifiers). Additionally, we can also set a negative lookahead, e.g. the password must not contain specific expressions like “password”, dates of birth etc.

Flags
It is important to note that when working with regular expressions it is also possible to set custom flags, which modify the behavior of the search. Probably the most important flag is the “i” flag, which indicates a case insensitive search, a search which ignores the differences between uppercase and lowercase characters.
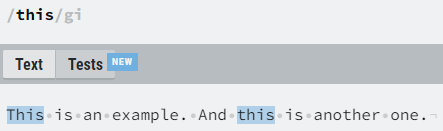
Practical examples
Some practical examples of regular expressions for extraction of specific information:
- a simple e-mail pattern,
- ^\w+@[a-zA-Z_]+?\.[a-zA-Z]{2,3}$
- MAC addresses,
- ^([0-9A-Fa-f]{2}[:-]){5}([0-9A-Fa-f]{2})$
- IP addresses.
- ^(?:[0-9]{1,3}\.){3}[0-9]{1,3}$
- ^(?:(?:25[0-5]|2[0-4][0-9]|[01]?[0-9][0-9]?)\.){3}(?:25[0-5]|2[0-4][0-9]|[01]?[0-9][0-9]?)$
Conclusion
All examples in this blog post were visualized using the online regex testing tool – RegExr (regexr.com), which we also recommend for learning and experimenting with regular expressions.
Regular expressions have proven to be an excellent tool for processing text data, from easier search in a large quantities of text data, over browsing web pages, dealing with databases to implementation of input validation systems. We hope that this regular expressions crash course will give you solid skills to start using them for your own adventures.
In case you have any questions regarding the usage of regular expressions, or if you need help in constructing the right regex which will cover all needed cases (and ignore the unwanted), feel free to contact the author of this post at domagoj.maric@megatrend.com.

