Blog
DataOps paradigma za bolje razumijevanje podataka
U modernim informacijskim sustavima, neovisno o branši poslovanja, podaci kojima tvrtka raspolaže su glavni pokretač za inovacije i održavanje prednosti ispred konkurencije. Razumijevanje vlastitih digitalnih podataka s kojima se raspolaže je ključni faktor za shvaćanje poslovnih trendova i prilika, izradu analitike i statistike poslovanja te pomaže i ubrzava put prema AI–u (journey to AI).
Prema istraživanjima s kraja 2019. godine, 89% poduzeća ima problema s upravljanjem podacima (Data Management) gdje najveći dio problema čini veliko kašnjenje u dovršetku projekata za uvid u podatke (izvješća itd.) te samim time nedostatak povjerenja u temeljne podatke koji se stvaraju zbog toga.
Razumijevanje poslovnih ciljeva organizacije presudno je za razvijanje učinkovite podatkovne strategije u područjima analitike i umjetne inteligencije. Kako bi se uspješno zadovoljilo potrebe tržišta, točnije, klijenta, sam uspjeh ovisi o racionalizaciji podatkovnih operacija (data operations) s integriranom podatkovnom protočnom strukturom (data pipeline) koja pruža cjelovit i konzistentan prikaz poslovanja u bilo kojem trenutku.
Brže dobivanje rezultata iz više različitih izvora podatka poboljšava operativnu učinkovitost i djelotvornost te bolje donošenje odluka neovisno o vrsti poslovnog odjela. Također, uz samu brzinu dobivanja rezultata iz podataka, važno je da su dobiveni podaci pouzdani i spremni za poslovanje (business ready).
Organizacijama koje traže transformaciju unutar svojih podatkovnih operacija, tehnologija automatizacije procesa može uvelike pomoći i pružiti konkurentsku prednost. Ukupna metodologija, točnije, paradigma načina sakupljanja, obrade, racionalizacije i prikaza podataka se naziva DataOps.
Što je DataOps?
DataOps paradigma, točnije, metodologija, je način za organizaciju ljudi, procesa i tehnologije za brzu isporuku pouzdanih i visokokvalitetnih podataka svim korisnicima istih.
Sama praksa DataOps je usredotočena na omogućavanje suradnje u cijeloj organizaciji kako bi se pokrenula agilnost, brzina isporuke i nove inicijative s podacima (agility, speed and data initiatives). Koristeći moć automatizacije, DataOps je dizajniran za rješavanje izazova povezanih s neučinkovitošću u pristupu, pripremi, integraciji i dostupnosti podataka.
Potencijalne koristi DataOps–a uključuju značajna povećanja produktivnosti u isporuci informacija i podataka pojedincima te poboljšanje procesa radi postizanja učinkovitosti i optimizacije.
Automatizirane podatkovne operacije koje uključuju AI inicijative vođene podacima (AI data–led initiative) mogu pomoći u postizanju sljedećih rezultata:
- Isporučivanje integriranih podataka koji pokreću analitiku i umjetnu inteligenciju spremnih za korištenje
- Postizanje operativne učinkovitosti
- Omogućavanje privatnosti i usklađenosti podataka (data privacy and compliance)
DataOps nije DevOps
U današnje vrijeme pojam DevOps–a je već vrlo raširen i donekle svima poznat. Velik broj organizacija već je implementirao određene razine DevOps–a unutar svojih razvojnih disciplina. Zbog sličnosti konvenciji imenovanja metodologija, unatoč tome što obje tehnike u praksi služe za kreiranje najboljih operativnih praksi, svaka od ove dvije metodologije ima svoju jedinstvenu funkciju i mjesto unutar organizacije.
Primarna razlika između navedene dvije metodologije je u osnovnom cilju: DevOps se koristi u razvoju i isporuci softvera, dok DataOps, kao što je već i navedeno, služi za omogućavanje pouzdanih, visokokvalitetnih podataka, spremnih za sve oblike korištenja i dostupnih za brzu upotrebu.
Daljnjom raščlambom razlika možemo navesti sljedeće karakteristike DataOps–a:
- Poticanje kontinuirane i brze inovacije posla omogućujući samoposlužni pristup (self–service access) pouzdanim, visokokvalitetnim podacima za sve korisnike
- Omogućavanje kontinuirane isporuke podataka automatizacijom upravljanja podacima (data governance) i integracije, istovremeno štiteći regulatorne probleme (regulatory concerns)
- Osiguravanje povratne sprege za kontinuirano učenje od svih korisnika podataka praćenjem i optimizacijom protoka podataka (data pipeline)
- Ispravljanje neusklađenosti ljudi i ciljeva njegujući bliže veze između podrške IT sustava, operative i poslovanja (operations and business)
- Ubrzavanje isporuke promjena i poboljšavanje kvalitete isporuke uvođenjem automatizacije tijekom ciklusa isporuke podataka
- Poboljšavanje uvida u stvarnu vrijednost metapodataka i podataka korištenjem dobivenih rezultata za ukupnu optimizaciju.
DevOps za razliku od prethodno navedenih, ima sljedeće karakteristike:
- Ubrzavanje kontinuiranog uvođenje ideja omogućavanjem suradničkog razvoja i testiranja u lancu razvoja softvera
- Omogućavanje kontinuirane isporuke inovacija automatiziranjem procesa isporuke softvera i uklanjanjem otpada, istovremeno pomažući u rješavanju regulatornih problema
- Omogućavanje povratne sprege za kontinuirano učenje od klijenata nadgledanjem i optimizacijom softverskih inovacija
- Ispravljanje neusklađenosti ljudi i ciljeva njegujući bliže veze između programera, operative i poslovanja
- Ubrzavanje uklanjanja pogrešaka u isporuci promjena uvođenjem automatizacije tijekom razvojnog ciklusa
- Poboljšavanje uvida u stvarnu vrijednost aplikacija korištenjem povratnih informacija klijenata u svrhu poticanja procesa optimizacije razvojnog sustava.
Ljudi, proces i tehnologija
DataOps je orkestracija ljudi, procesa i tehnologije, a za održavanje predanosti prakse DataOps-a potrebna je suradnja svih funkcija. Potreban je fokus na njegovanju praksi i procesa upravljanja podacima koji poboljšavaju brzinu i točnost analitike.
DataOps podržava visoko produktivne timove s tehnologijom automatizacije koji pomažu u postizanju povećanja učinkovitosti kako u projektnim rezultatima, tako i u vremenu potrebnom za isporuku podataka. S obzirom na to da više poslovnih segmenata zahtijeva i želi upravljati podacima za postizanje kontekstualnih uvida, ciljevi DataOps–a su sljedeći:
- Povećanje kvalitete i brzine protoka podataka do organizacije
- Iskorištavanje predanosti vodstva za podršku i održavanje vizije na temelju podataka u cijelom poslu.
Ova vrsta transformacijske promjene započinje razumijevanjem istinskih ciljeva poslovanja:
- Kako podaci informiraju o odlukama i uslugama koje utječu na kupce?
- Kako podaci mogu pomoći u održavanju konkurentske prednosti na tržištu?
- U rješavanju kojih financijskih problema nam mogu pomoći podaci?
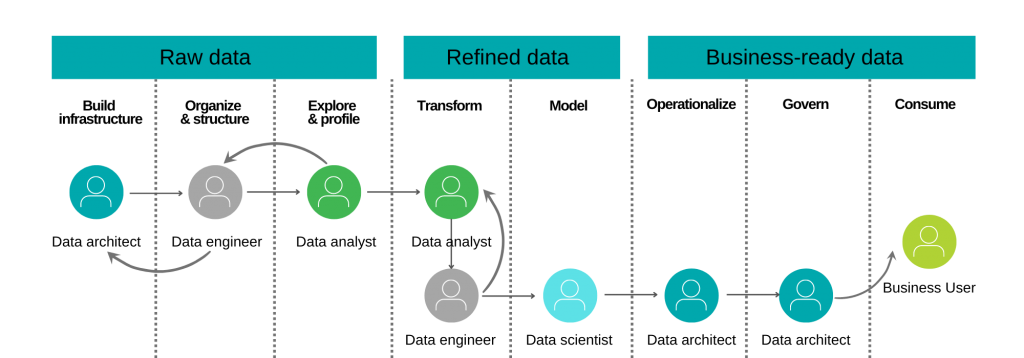
Srž DataOps-a je informacijska arhitektura tvrtke. Znate li svoje podatke? Vjerujete li svojim podacima? Možete li brzo otkriti pogreške? Možete li postupno unositi promjene bez da ste “razbili” cijeli protok podataka (data pipeline)? Da bi se odgovorilo na ova pitanja, prvi korak je inventarizacija alata i praksi korištenih u upravljanju i integraciji podataka.
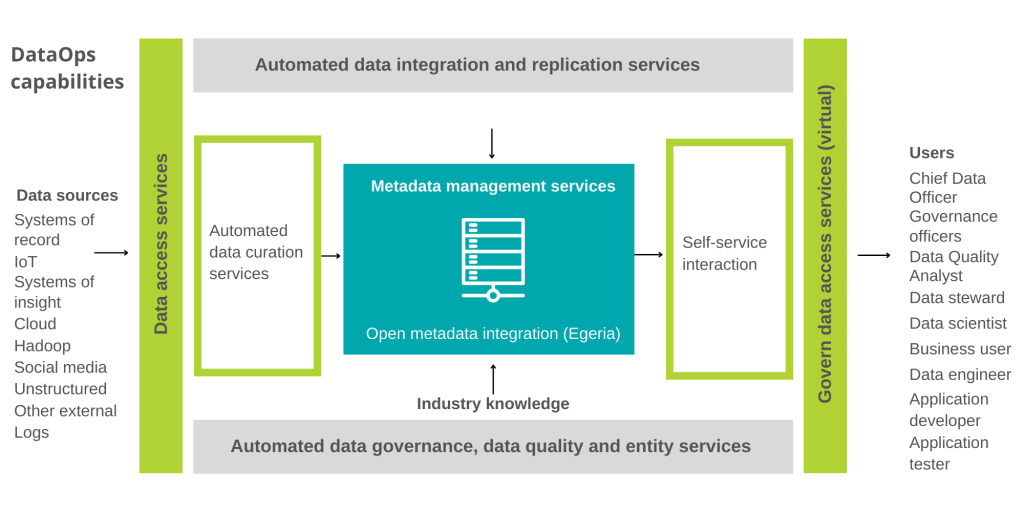
Kada se razmišlja o alatima koji podržavaju DataOps praksu unutar tvrtke, potrebno je razmisliti kako automatizacija u ovih pet kritičnih područja može transformirati protok podataka (data pipeline):
1. Usluge čuvanja podataka (data curation services)
2. Upravljanje metapodacima (metadata management)
3. Upravljanje podacima (data governance)
4. Upravljanje matičnim podacima (master data management)
5. Samoposlužna interakcija (self-service interaction).
Pružanje podataka spremnih za poslovanje uključuje sve ove aspekte, a svaka DataOps praksa mora uključivati holistički pristup koji uključuje svih 5 aspekata.
IBM DataOps
IBM DataOps pomaže u isporuci podataka spremnih za poslovanje pružajući vodeću tehnologiju u industriji koja radi zajedno s automatizacijom i omogućenom umjetnom inteligencijom (AI-enabled automation), opremljena je infuzijskim upravljanjem (infused governance) i moćnim katalogom znanja kako bi se operacionalizirali kontinuirani, visokokvalitetni podaci u cijelom poslu. Povećava učinkovitost, kvalitetu podataka, pronalaženje i ugrađuje upravljačka pravila kako bi se pružio protok podataka i samoposluživanje podataka pravim ljudima u pravo vrijeme iz bilo kojeg izvora.
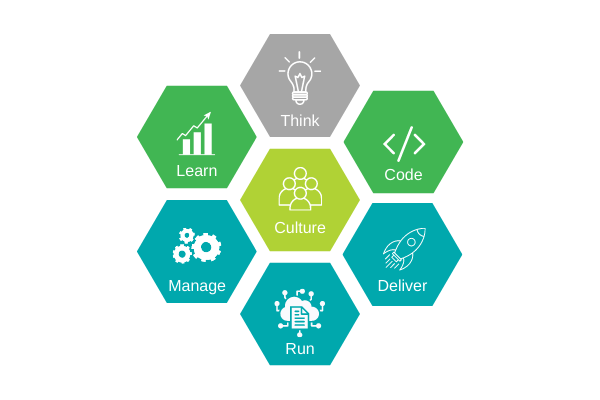
IBM je identificirao šest faza u životnom ciklusu DataOps–a, te uz tih šest faza i neophodna kulturna razmatranja, kako bi se uspješno provodile prakse DataOps–a. Uz interno usvajanje DataOps-a taj je pristup temelj uspješnog puta za transformaciju.
– Razmišljanje. (Think) Konceptualizacija, usavršavanje i određivanje prioriteta sposobnosti
– Programiranje. (Code) Generiranje, poboljšanje, optimizacija i ispitivanje značajki
– Dostavljanje. (Deliver) Automatizirana proizvodnja i dostava značajki
– Pokretanje. (Run) Usluge, opcije i mogućnosti potrebne za pokretanje
– Upravljanje. (Manage) Stalno praćenje, podrška i povratak funkcionalnosti
– Učenje. (Learn) Kontinuirano učenje i povratne informacije na temelju rezultata eksperimenata
Što IBM nudi?
IBM nudi nove inovativne mogućnosti koje uključuju ugrađeno strojno učenje (ML), AI automatizaciju, integrirano upravljanje (infused governance) i moćan katalog podataka (data catalog) za operativne i kontinuirane visokokvalitetne podatke u cijelom poslovanju. Učinkovitost DataOps–a ovisi o ekstremnoj automatizaciji komponenata podatkovne tehnologije koje se koriste za podatkovni tok (data pipeline).
IBM Cloud Pak for Data, uključujući IBM Watson katalog znanja (WKC) može odgovoriti na ove zahtjeve na učinkovit, robustan, automatiziran i ponovljiv način.
IBM Cloud Pak for Data Server može riješiti potrebu za kretanjem podataka, njihove objave i korištenja u podatkovnom toku, pomažući pritom u osiguranju kvalitete podataka i provođenju pravila. Uz učinkovito upravljanje kontrolom izvora, proces se može automatizirati i učinkovito izvršavati.
Ugrađeno strojno učenje (ML) u IBM Watson Knowledge Catalog–u za IBM Cloud Pak for Data dopunjuje postupak automatizacije i optimizira ga sa svakom iteracijom za robustan tok podataka.
IBM Cloud™ DevOps Insights može pomoći u pružanju operativnog uvida i vizualizacije toka podataka. Pomaže u provođenju mjera sigurnosti i kvalitete koje se kontinuirano nadgledaju, otkriva sve neočekivane varijacije i generira operativne statistike na temelju ekstremne automatizacije i prilagođene integracije s IBM Cloud Pak for Data.
Apache Airflow i NiFi mogu pomoći u dizajniranju tijeka rada i njegovoj orkestraciji.
Korištenje ekstremne automatizacije pomoću REST krajnjih točaka (REST endpoints) zajedno s parametrizacijom može pomoći u dinamičnom odabiru određenih skupova podataka ili okoline, te promijeniti ponašanje bez utjecaja na izvorni kod toka (pipeline) i prilagoditi se svakodnevnim potrebama stručnjaka za analitiku podataka.
Zašto implementirati DataOps?
Organizacije koje su uspješno implementirale DataOps znaju kojim podacima imaju pristup, vjeruju značenju podataka i njihovoj kvaliteti i koriste svoje podatke do maksimuma.
Podaci imaju vrijednost onda kada pouzdani podaci spremni za poslovanje pomažu u postizanju različitih uvida, operativne izvrsnosti, suradnje i konkurentske prednosti.
Ukoliko želite smanjiti troškove s učinkovitijom obradom podataka i analitikom s jedinstvenim setom proizvoda i kvalitetnijim utroškom resursa, isporučivati agilno i kontinuirano nove analitičke proizvode kroz DataOps, podići produktivnost, kooperaciju na jedinstvenoj integriranoj platformi, ili doznati više podataka javite se našim stručnjacima.

