Blog ENG
DataOps paradigm for better data insights
In modern information systems, regardless of the industry, the data available to the company is the main driver for innovation and maintaining an advantage over the numerous competition. Understanding one’s own digital data is a key factor in understanding business trends and opportunities, as well as producing business analytics and statistics, and helping and accelerating the journey to AI.
According to research from the end of 2019, 89% of companies have problems with data management where most of the problems are unnecessarily long delays in completing projects for data insight (reports, etc.) and accordingly lack of confidence in the underlying data generated because of that.
Understanding the organization’s business goals is crucial to developing an effective data strategy in the areas of analytics and artificial intelligence. In order to successfully meet the needs of the market, more precisely, the client, the success itself mostly depends on the rationalization of data operations with an integrated data pipeline that provides a complete and consistent aspect of business at any time.
Getting results faster from multiple different data sources improves operational efficiency and effectiveness. Moreover, it enhances better decision-making process regardless of the type of business. Also, in addition to the speed of obtaining results from the data, it is important that the data which is obtained is reliable and business-ready.
For organizations seeking transformation within their data operations, the technology of process automation can greatly help provide a competitive advantage. The overall methodology, more precisely, the paradigm of data collection, processing, rationalization and presentation is called DataOps.
What is DataOps
The DataOps paradigm, more precisely, the methodology, is a way to organize people, processes and technologies for fast delivery of reliable and high-quality data to all its users.
The practice of DataOps itself is focused on enabling collaboration across the organization to drive agility, speed of delivery and new data initiatives (agility, speed and data initiatives). Utilizing the power of automation, DataOps is designed to address the challenges associated with inefficiencies in accessing, preparing, integrating, and availability of data.
The potential benefits of DataOps include significant increases in productivity in delivering information and data to individuals and improving processes to achieve efficiency and optimization.
Automated data operations involving data-led AI initiatives can help achieve the following results:
- deliver integrated data that stimulates analytics and artificial intelligence ready for use
- achieving operational efficiency
- enabling data privacy and compliance
DataOps is not DevOps
Nowadays, the term DevOps is already very widespread and familiar to everyone. Various organizations have already implemented certain levels of DevOps within their development disciplines. Due to the similarity of naming these methodologies, despite the fact that both techniques in practice serve to create the best operational practices, each of these two methodologies has its own unique function and place within the organization.
The primary difference between the two methodologies is the main goal: DevOps is used in software development and delivery, while DataOps, as already mentioned, serves to provide reliable, high-quality data, ready for all uses and available for fast use.
By further analysis of the differences, we can list the following characteristics of DataOps:
- encouraging continuous and rapid business innovation by enabling self-service access to reliable, high-quality data for all users
- enabling continuous data delivery by automating data governance and integration, while protecting regulatory concerns
- providing feedback for continuous learning from all data users by monitoring and optimizing the data flow (data pipeline)
- correcting inconsistencies between people and goals by fostering closer links between IT support, operations and business
- accelerating the delivery of changes and improve the quality of delivery by introducing automation during the data delivery cycle
- improving insight into the real value of metadata and data by using the obtained results for overall optimization.
DevOps, unlike the above, has the following features:
- accelerating the continuous introduction of ideas by enabling collaborative development and testing in the software development chain
- enabling continuous delivery of innovations by automating software delivery and removing disposal processes, while helping to solve regulatory problems
- providing feedback for continuous learning from clients by monitoring and optimizing software innovations
- correcting inconsistencies between people and goals by nurturing closer links between developers, operations and business
- advancing the elimination of errors in the delivery of changes by introducing automation during the development cycle
- improving insight into the real value of applications by using customer feedback to encourage the development system optimization process.
People, process and technology
DataOps is an orchestration of people, processes, and technology, and it requires the collaboration of all functions. A focus is essential on nurturing data management practices and processes that improve the speed and accuracy of analytics.
DataOps supports highly productive teams with automation technology that helps achieve increased efficiency; both in project results and in the time required to deliver data.
Given that multiple business segments feel necessity to manage data to achieve contextual insights, the objectives of DataOps are as follows:
- Increasing the quality and speed of data flow to the organization
- Leverage the commitment of management to support and maintain a vision based on data throughout the business.
This type of transformational change begins with understanding the true goals of the business:
- How does the data inform about decisions and services that affect customers?
- How can data help maintain a competitive advantage in the market?
- What financial problems can data help us solve?
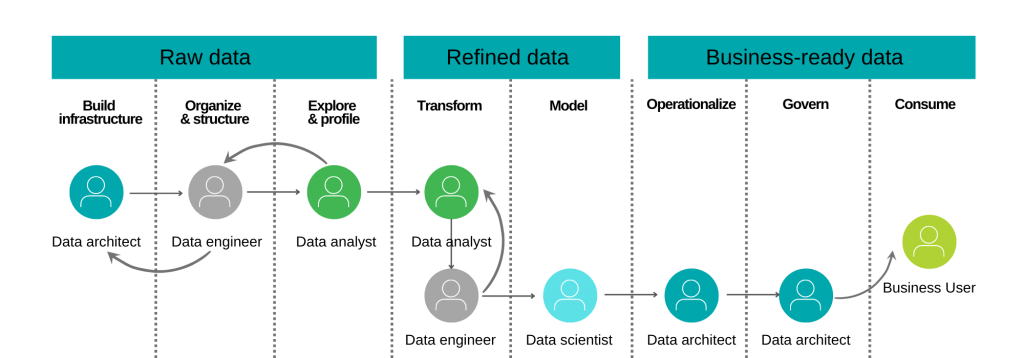
The core of DataOps is the company’s information architecture. Do you know your data? Do you trust your data? Can you detect errors quickly? Can you make changes gradually without breaking the entire data pipeline? To answer these questions, the first step is to inventory the tools and practices used in data management.
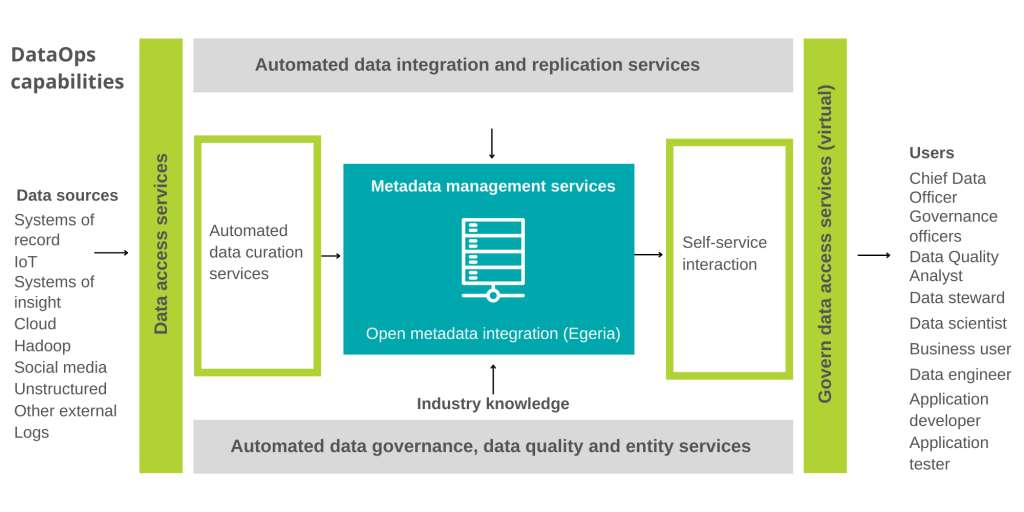
When considering tools that support the DataOps practice within the company, it is necessary to consider how automation in these five critical areas can transform the data pipeline:
1. Data curation services
2. Metadata management
3. Data governance
4. Master data management
5. Self-service interaction.
Providing business-ready data includes all of these aspects, and any DataOps practice must include a holistic approach that includes all 5 aspects.
IBM DataOps
IBM DataOps helps deliver business-ready data by providing industry-leading technology that works in conjunction with AI-enabled automation, equipped with infused governance and a powerful knowledge catalog to streamline continuous, high-quality data through the whole business. It increases efficiency, data quality, retrieval and incorporates management rules to ensure data flow and self-service to the right people at the right time from any source.
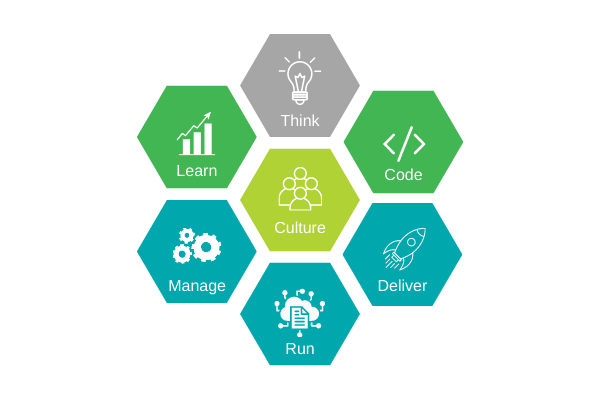
IBM has identified six phases in the DataOps lifecycle, and in addition to these six phases, the unavoidable cultural considerations to successfully implement DataOps practices. Along with the internal adoption of DataOps, this approach is crucial for a successful path to transformation.
– Thinking. (Think) Conceptualizing, improving, and prioritizing competencies
– Programming. (Code) Generating, improving, optimizing and testing features
– Delivery. (Deliver) Automated production and feature delivery
– Launch. (Run) Services, options and features needed to run
– Management. (Manage) Constant monitoring, support and return of functionality
– Learning. (Learn) Continuous learning and feedback based on experimental results
What IBM offers?
IBM offers new innovative features that include embedded machine learning (ML), AI automation, integrated management (infused governance), and a powerful data catalog for operational and continuous high-quality business-wide data. The effectiveness of DataOps depends on the extreme automation of the data technology components used for the data pipeline.
The IBM Cloud Pak for Data, including the IBM Watson Knowledge Catalog (WKC), can meet these requirements in an efficient, robust, automated, and replicable manner.
IBM Cloud Pak for Data Server can address the need to move data, publish it, and use it in the data flow, while helping to ensure data quality and enforce policies. With efficient resource control management, the process can be automated and executed skilfully.
Built-in machine learning (ML) in the IBM Watson Knowledge Catalog for IBM Cloud Pak for Data complements the automation process and optimizes it with each iteration for a robust data flow.
IBM Cloud ™ DevOps Insights can help provide operational insight and visualization of data flow. It helps implement security and quality measures that are continuously monitored. Also, it detects all unexpected variations, and generates operational statistics based on extreme automation and customized integration with IBM Cloud Pak for Data.
Apache Airflow and NiFi can help design a workflow and orchestrate it.
Using extreme automation with REST endpoints along with parameterization can help dynamically select specific datasets or environments, change behaviour without affecting the pipeline, and adapt to the day-to-day needs of data-analytics professionals.
Why implement DataOps?
Organizations that have successfully implemented DataOps know exactly what data they have access to, they trust the meaning of the data and its quality, and use their data to the maximum.
Data has value only when reliable business-ready data helps to achieve different insights, operational excellence, collaboration, and competitive advantage.
If you want to reduce costs with more efficient data processing and analytics with a unique set of products and better resource consumption, or to deliver agile and continuous new analytical products through DataOps, increase productivity, cooperation on a single integrated platform, or find out more contact our experts.

