IRI Voracity je moderna softverska platforma za:
- Otkrivanje podataka — pretraživanje, izdvajanje, strukturiranje, profiliranje, klasifikaciju i izradu dijagrama skupova podataka
- Integraciju podataka — izdvajanje, pretvaranje, učitavanje (ETL), hvatanje promjena podataka (change data capture), pivotiranje itd.
- Migraciju podataka — prema vrsti podataka, formatima datoteka, endian tipovima te konverziju ili replikaciju baza podataka
- Upravljanje podacima — čišćenje, maskiranje, testni podaci, glavni podaci i upravljanje metapodacima
- Analitika — ugrađeni izvještaji (embedded reporting), integracija BIRT-a (Bussiness Intelligence Reporting Tools) i dashboarda ili obrada podataka
- Brzo traženje i maskiranje podataka (sa ili bez Hadoopa)
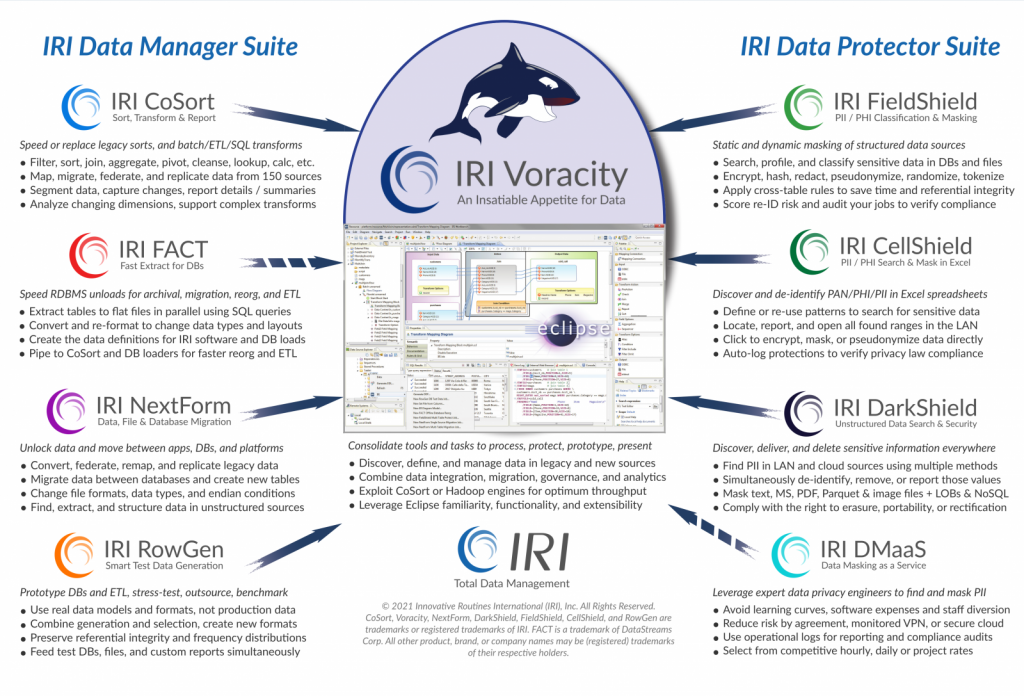
IRI Voracity je jedina end-to-end softverska platforma za brzo, pristupačno i ergonomsko upravljanje cijelim životnim ciklusom podataka; kombinira otkrivanje podataka, integraciju, migraciju, upravljanje i analitiku u jednom ekosustavu.
Svrha Voracityja je da bude centralizirano područje za razvrstavanje podataka i sveobuhvatni stog rješenja za otkrivanje podataka, integraciju, migraciju, upravljanje i analitiku. IRI promiče Voracity kao “jedinu pristupačnu platformu velike brzine za upravljanje podacima u datotekama, bazama podataka, HDFS-ima i aplikacijama u oblaku, od profiliranja do prezentacije.”
Smanjuje krivulje troškova, složenosti i rizika za razliku ostalih ETL i sličnih alata drugih dobavljača, nepovezanih Apache projekata i specijaliziranog softvera budući da uključuje profiliranje i klasifikaciju, integraciju i udruživanje, čišćenje i obogaćivanje, objedinjavanje i provjeru valjanosti, maskiranje i šifriranje, izvještavanje i pripremu, testiranje na svim podacima.
IRI Voracity pokreće CoSort ili Hadoop i ima front – end u Eclipseu, a pruža rezultate koje tvrtke trebaju, konsolidaciju koju IT želi i pristupačnost kroz pružanje superiorne brzine kretanja podataka, sigurnosti usmjerene na podatke i uštede za CDO-e, CISO-e, DBA-e, arhitekte skladišta podataka i podatkovne znanstvenike.
Voracity koristi popularno (i besplatno) grafičko integrirano razvojno okruženje (IDE) pod nazivom IRI Workbench. Budući da je izgrađen na Eclipseu, GUI za Voracity automatski je poznat milijunima korisnika i potpuno je proširiv stog rješenja. Mnogi besplatni i komercijalni dodaci mogu se otvoriti u Voracity radnim prostorima i pokrenuti unutar Voracity radnih tokova.
Koristeći ove fleksibilne Eclipse „radne prostore“, različiti korisnici mogu raditi sami ili u timu na profiliranju i klasificiranju, integraciji i usklađivanju, čišćenju i maskiranju, prototipiranju ili repliciranju, te miješanju ili analiziranju svojih podataka, kao i praćenju njihovih promjena kroz vrijeme.
IRI Voracity rješava izazove volumena, raznolikosti, brzine, istinitosti i vrijednosti (5V – volume, variety, velocity, veracity, value) u pretvaranju velikih podataka (Big Data) u informacije koje se mogu primijeniti, pošto koristi dokazanu izvedbu programa CoSort SortCL ili opcijskih Hadoop procedura za kretanje, manipulaciju, maskiranje i razbijanje strukturiranih, polustrukturiranih, i nestrukturiranih podataka, a postojeći korisnici Hadoop-a mogu jednostavno iskoristiti Voracity mogućnosti u cijelosti ili djelomično.
Samo u Voracityu je moguće:
- KLASIFICIRATI, profilirati i dijagramirati enterprise izvore podataka
- Ubrzati ili NAPUSTITI postojeće načine sortiranja i ETL alate
- MIGRIRATI podatke za modernizaciju i OBRADITI podatke za analizu
- PRONAĆI PII (Personal Identifiable Information) podatke posvuda i dosljedno ih MASKIRATI radi referentnog integriteta
- Ocijeniti rizik ID-eva i ANONIMIZIRATI kvazi-identifikatore
- Kreirati i upravljati DB podskupovima ili inteligentno sintetizirati TESTNE podatke
- Pakirati, zaštititi i osigurati VELIKE podatke (Big Data)
- Potvrditi, pročistiti, obogatiti i objediniti podatke za poboljšanje njihove KVALITETE
- Upravljanje metapodacima i MASTER podacima.
Koristite Voracity da biste se pridržavali zakona o privatnosti podataka, uklanjali nepotrebne podatke i upravljali jezerom podataka (Data Lake), poboljšali pouzdanost svoje analitike i stvorili sigurne, pametne testne podatke.