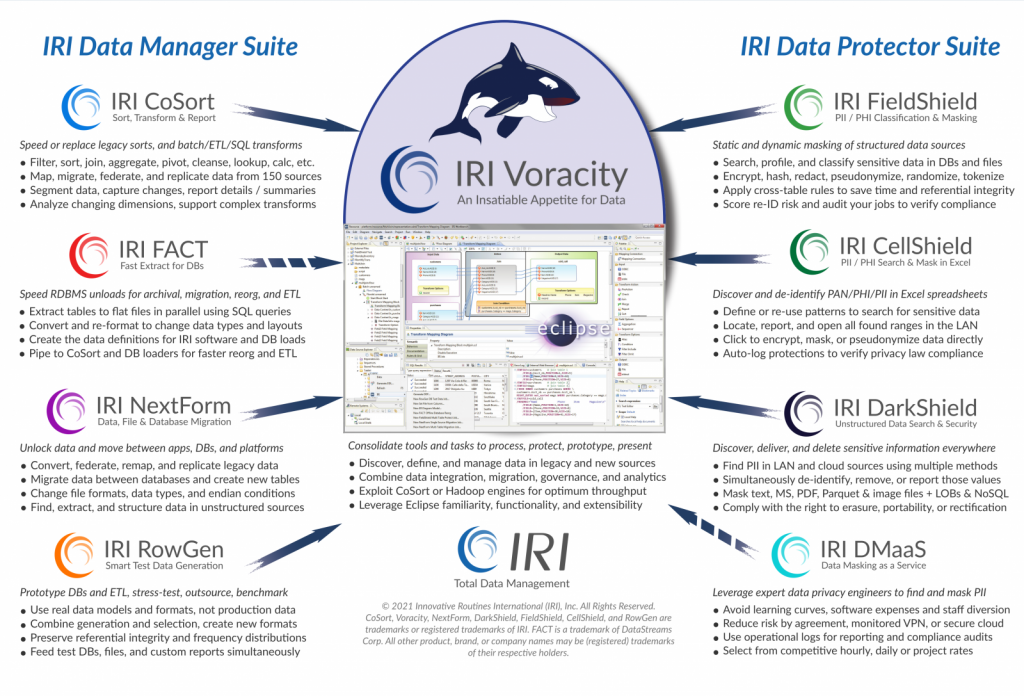
IRI Voracity is a modern software platform for:
- Data Discovery — search, extract, structure, profile, classify, and diagram data sets
- Data Integration — extract, transform, load (ETL), change data capture, pivoting, etc.
- Data Migration — data type, file format, endian, and database conversion or replication
- Data Governance — cleansing, masking, test data, master data and metadata management
- Analytics — embedded reporting, BIRT and dashboard integration, or data wrangling
- Fast Data Munging and Masking (With or Without Hadoop)
IRI Voracity is the only end-to-end software platform for fast, affordable, and ergonomic data life-cycle management; it combines data discovery, integration, migration, governance, and analytics in a single ecosystem.
The purpose of Voracity is to be a centralized data marshalling area and one-stop solution stack for data discovery, integration, migration, governance, and analytics. IRI touts Voracity as the “only affordable, high-speed platform for managing data in flat files, DBs, HDFS, and cloud apps, from profiling to presentation.”
Voracity bends the multi-tool cost, complexity, and risk curves away from mega-vendor ETL packages, disjointed Apache projects, and specialized software since it includes data: profiling and classification, integration and federation, cleansing and enrichment, unification and validation, masking and encryption, reporting and preparation, sub setting and testing.
IRI Voracity total data management is powered by CoSort or Hadoop and front-ended in Eclipse, and it delivers the outcomes that businesses need, the consolidation that IT wants, and the affordability through the provision of superior data movement speed, data-centric security and savings for CDOs, CISOs, DBAs, data warehouse architects, and data scientists.
Voracity uses a popular (and free) graphical integrated development environment (IDE) called IRI Workbench. Because it is built on Eclipse, the GUI for Voracity is automatically familiar to millions of users, and is a fully extensible solution stack. Many free and commercial plug-ins can open in Voracity’s user workspaces and run within Voracity workflows.
Using these flexible Eclipse “workspaces,” different stakeholders can work alone or in teams to profile and classify, integrate and harmonize, clean and mask, prototype or replicate, and blend or analyze their data, as well as track its changes through time.
Voracity addresses the volume, variety, velocity, veracity, and value challenges in turning big data into actionable information as it leverages the proven performance of the CoSort SortCL program or optional Hadoop engines for moving, manipulating, masking and munging structured, semi-structured, and unstructured data while the current Hadoop users can seamlessly leverage Voracity capabilities in whole or part.
Only in Voracity can you:
Only in Voracity can you:CLASSIFY, profile and diagram enterprise data sources
Speed or LEAVE legacy sort and ETL tools
MIGRATE data to modernize and WRANGLE data to analyze
FIND PII everywhere and consistently MASK it for referential integrity
Score re-ID risk and ANONYMIZE quasi-identifiers
Create and manage DB subsets or intelligently synthesize TEST data
Package, protect and provision BIG data
Validate, scrub, enrich and unify data to improve its QUALITY
Manage metadata and MASTER data.
Use Voracity to comply with data privacy laws, de-muck and govern the data lake, improve the reliability of your analytics, and create safe, smart test data.