Blog
Poslovanje protkano podacima
Svaka organizacija traži načine da otključa svoje podatke kako bi bila inovativna i ostala konkurentna. Većina se suočava sa značajnim izazovima prikupljanja, pohranjivanja i analize podataka jer su podatkovna okruženja postala su sve složenija. Složenost nastaje zbog nekoliko čimbenika:
- podaci se nalaze na puno različitih mjesta, takozvanih podatkovnih silosa
- povećava se volumen podataka koji se generiraju i prikupljaju
- da bi podaci bili dostupni našim analitičkim procesima, često se dodatno kopiraju i transformiraju
- što više podataka i izvora podataka imamo, to je složenije razumjeti kako su podaci povezani održavati visoku razinu kvalitete podataka
Izazovi upravljanja podacima
Posljedica svega toga je jaz koji nastaje između podataka koji su nam dostupni i onih podataka koje razumijemo odnosno koristimo s razumijevanjem. Bitno je raditi na smanjenje tog jaza jer to može značiti veću prodaju, raniju detekciju prijevara, smanjenje troškova ili kreiranje novog inovativnog proizvoda. Tvrtke koje to uspijevaju s pravom se mogu nazivati data driven tvrtkama. Problem je što postizanje toga nije jednostavno i na neki način postaje privilegija manjine koja ima snagu to ostvariti i koja može izgraditi talentirane i uspješne podatkovne timove. Jedan od načina kako tome pristupiti je omogućiti da što više ljudi unutar organizacije ima pristup podacima i alate potrebne da za rad s njima. Što više osoba koristi podatke i postavlja pitanja generirati će se veći broj hipoteza. Dio tih hipoteza pokazati će se validne kao ideje koje se mogu isprobati a ako se pokažu korisne u konačnici mogu i završiti u upotrebi.
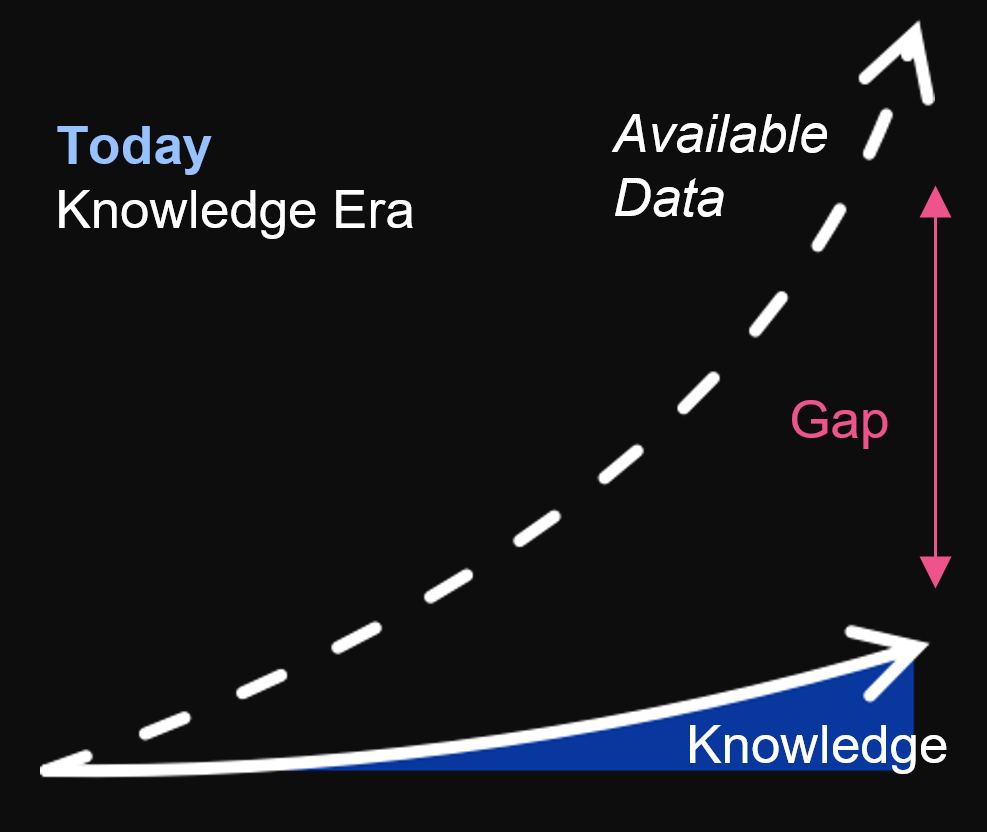
Drugi izazov koji se pojavljuje je problem integracije svih tih podataka. U prošlosti su organizacije pokušavale riješiti probleme pristupa podacima bilo integracijom od točke do točke (point-to-point) ili uvođenjem podatkovnih čvorišta (data hub). Niti jedno od njih nije prikladno kada su podaci visoko distribuirani i razdvojeni. Integracije od točke do točke dodaju veliki trošak za svaku dodatnu krajnju točku koja se treba povezati, što znači da taj pristup nije skalabilan. Podatkovna čvorišta s vremenom postaju jako kompleksa i izazov je održavati svu logiku na i sve podatke na jednom mjestu
AI ljestvica
Za uspješnu borbu s tim izazovima potrebno je izgraditi modernu podatkovnu infrastrukturu. “AI ljestvica” (AI ladder), koncept koji je razvio IBM, omogućuje modernizaciju informacijske arhitekture u četiri ključna koraka pružajući pritom organizacijama razumijevanje gdje se nalaze na njihovom AI putu i služi kao okvir za određivanje na koji korak se trebaju usredotočiti. Kao vodeće načelo za organizacije u transformaciji poslovanja pruža četiri područja koja treba razmotriti:
1. Prikupljanje (collect): Učinite podatke jednostavnim i dostupnim – prikupljajte podatke svih vrsta, bez obzira gdje se oni nalaze, omogućujući fleksibilnost u odnosu na stalno mijenjajuće izvore podataka, istodobno smanjujući troškove, neučinkovitost i kvalitetu povezanu s tradicionalnim upravljanjem podacima.
2. Organizacija (organize): Stvorite analitički temelj spreman za poslovanje – organizirajte sve podatke u pouzdanu poslovno spremnu podlogu s ugrađenim upravljanjem, zaštitom i usklađenošću (data governance), bez obzira na to gdje se podaci nalaze.
3. Analiziranje (analyze): Gradite i skalirajte AI s povjerenjem transparentnošću – Analizirajte podatke na brže i pametnije načine, i iskoristite modele AI koji organizacijama omogućuju da steknu nove uvide i donesu bolje, pametnije odluke, bez tradicionalnih izazova i silosa.
4. Unošenje (infuse): operacionalizirajte AI tijekom cijelog poslovanja – primijenite AI u cijeloj tvrtki u više odjela i unutar različitih procesa, oslanjajući se na predviđanja, automatizaciju i optimizaciju koju podržava unificirana platforma.
Osim prolaska kroz četiri navedena koraka AI ljestvice velika korist se može dobiti uspostavom data fabric arhitekture. To je napredni način upravljanja podacima koji je usmjeren na podatke kako bi se omogućila dinamična i inteligentna orkestracija podataka u visoko distribuiranom podatkovnom krajoliku.
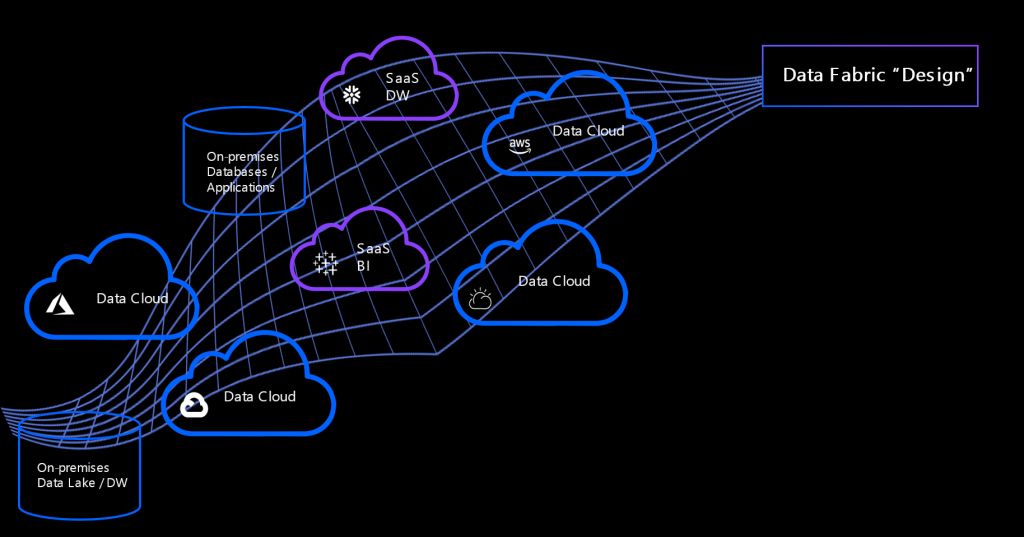
Data fabric arhitektura
Data fabric je zapravo apstrakcijski sloj koji omogućavam korištenje i dijeljenje podatak duž cijelog podatkovnog krajolika i može se logično podijeliti na četiri mogućnosti:
Znanje, uvidi i semantika
- Automatski obogaćuje otkrivena sredstva podataka znanjem i semantikom, omogućujući korisnicima da lakše pronađu i razumiju podatke
Jedinstveno upravljanje i usklađenost
- Omogućuje lokalno upravljanje metapodacima, ali podržava globalni jedinstveni pogled i provedbu politike
- Automatski primjenjuje pravila nad podacima
- Koristi napredne mogućnosti za automatsku klasifikaciju podataka
Inteligentna integracija
- Ubrzava rada podatkovnih inženjere kroz automatizirano kreiranje podatkovnih cjevovoda
- Omogućuje samoposlužno učitavanje i pristup svim podacima
- Automatski određuje najbolju način izvođenja upita uz optimiziranu raspodjelu radnog opterećenja
Orkestracija i životni ciklus
- Omogućuje kreiranje, testiranje, izvršavanje i nadzor podatkovnih cjevovoda
- Unosi AI sposobnosti u životni ciklus podataka
Primjenom data fabric arhitekture izbjegava se prekomjernog kopiranja podataka i optimizira se način na koji se podaci premještaju ili im se pristupa. Nekada ne možemo smanjiti količinu podataka ili složenost podatkovne mreže, ali možemo koristiti tehnike tako da se podaci dohvate najboljom mogućom metodom. Također na taj način se može uspostaviti visoko automatizirano i vođeno korisničko iskustvo.

IBM Cloud Pak for Data platforma
Da bi to sve ostvarili trebamo platformu a unutar IBM-u se platforma koja omogućava uspostavu data fabric arhitekture zove IBM Cloud Pak for Data. IBM Cloud Pak for Data se sastoji od bogatog skupa usluga za prikupljanja, organiziranja, upravljanja i analizu podataka. Najveća vrijednost ovog sustava leži u činjenici da je kompletan set alata i servisa potrebnih za kompletan rad s podacima implementiran u jednu integriranu platformu, čineći troškove za hardversku infrastrukturu manjima te smanjuje potrebno vrijeme i resurse za implementaciju i ukupno održavanje. U konačnici primjenom data fabric arhitekture i IBM Cloud Pak for Data može se omogućiti pristup bilo kome, bilo kojim podacima u bilo koje vrijeme i na bilo kojem mjestu, naravno ukoliko je je taj pristup autoriziran.

