Blog ENG
Integrate and engage all your organization’s data for better business outcomes
Every organization is looking for ways to unlock its data to be innovative and stay competitive. Most organizations face significant challenges in collecting, storing, and analyzing data as data environments become increasingly complex. Complexity is caused by several factors:
- Data is located in many different places, so-called data silos
- the volume of data generated and collected increases
- to make data available to our analytical processes, they are often further copied and transformed
- The more data and data sources we have, the more complex it is to understand how data is connected to maintain a high level of data quality
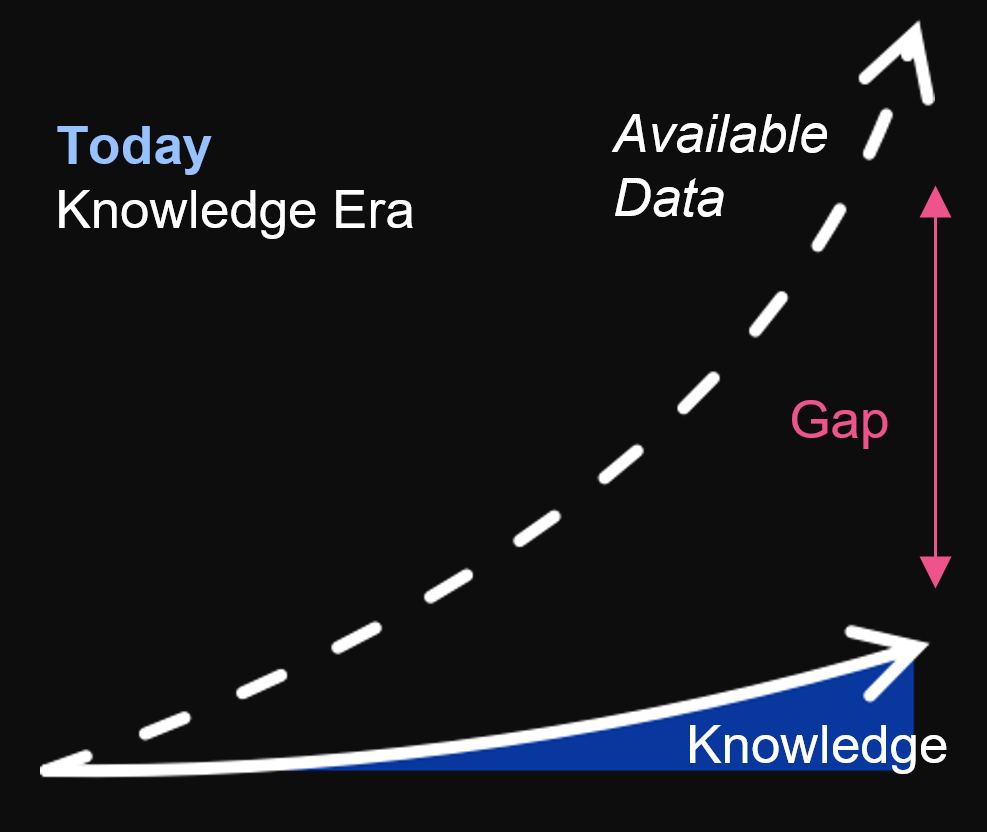
Data challenges
The consequence of all this is the gap that arises between the data available to us and those data that we understand or use with understanding. It is important to work on reducing this gap as this can mean higher sales, earlier fraud detection, cost reduction, or the creation of a new innovative product. Companies that succeed can rightly be called data-driven companies. The problem is that achieving this is not easy and in a way, it becomes the privilege of a minority that has the power to achieve this and that can build talented and successful data teams. One way to approach this is to allow as many people within the organization as possible to have access to the data and tools they need to work with it. The more people use the data and ask questions, the more hypotheses will be generated. Some of these hypotheses will prove valid as ideas that can be tested and if they prove useful they may end up in use.
Another challenge that arises is the problem of integrating all this data. In the past, organizations have tried to solve data access problems either by point-to-point integration or by introducing data hubs. None of this is appropriate when data is highly distributed and fragmented. Point-to-point integrations add a large cost to each additional endpoint that needs to be connected, meaning this approach is not scalable. Data hubs become very complex over time and the challenge is to keep all the logic on and all the data in one place.
AI ladder
To successfully fight these challenges, it is necessary to build a modern data infrastructure. The AI ladder, a concept developed by IBM, enables the modernization of information architecture in four key steps, providing organizations with an understanding of where they stand in their AI path and serving as a framework for determining which step to focus on. As a guiding principle for organizations in business transformation, it provides four areas to consider:
- Collect: Increase the ability of business and analytics users to consume all data in a self-service and governed way, decreasing time to gain insight from data while reducing cost and risk. Leverage all data needed across the enterprise.
- Organize: Apply a DataOps approach to managing data assets across the organization. By using tools to trace the origin of data from the source, to managing the governance and quality of that data, to making data easier to find, analytics and AI can be built on high-quality data assets, resulting in increased accuracy, faster deployment and reduced risk for the organization.
- Analyze: Analysis is no longer just for the data scientists and engineers. To increase use and deployment, users of all skill levels need to build and deploy analytics and AI. Collaborative tools, automation, and tools to detect accuracy help to put AI capabilities into the hands of more roles in the organization.
Infuse: Automate and infuse those models into real-world applications. Enable humans and machines or “bots” to cooperate and complete tasks at speed and scale. Automate common processes with AI-assisted intelligence and allow more time for people to work the complex tasks.
In addition to going through the four steps of the AI ladder, great benefits can be gained by establishing a data fabric architecture. It is an advanced data-driven way of data management to enable dynamic and intelligent orchestration of data in a highly distributed data landscape.
IBM Cloud Pak for Data is a fully integrated data and AI platform that enables organizations to work through all of the steps of the AI Ladder by collecting, organizing, and analyzing data, and then infusing AI throughout the business.
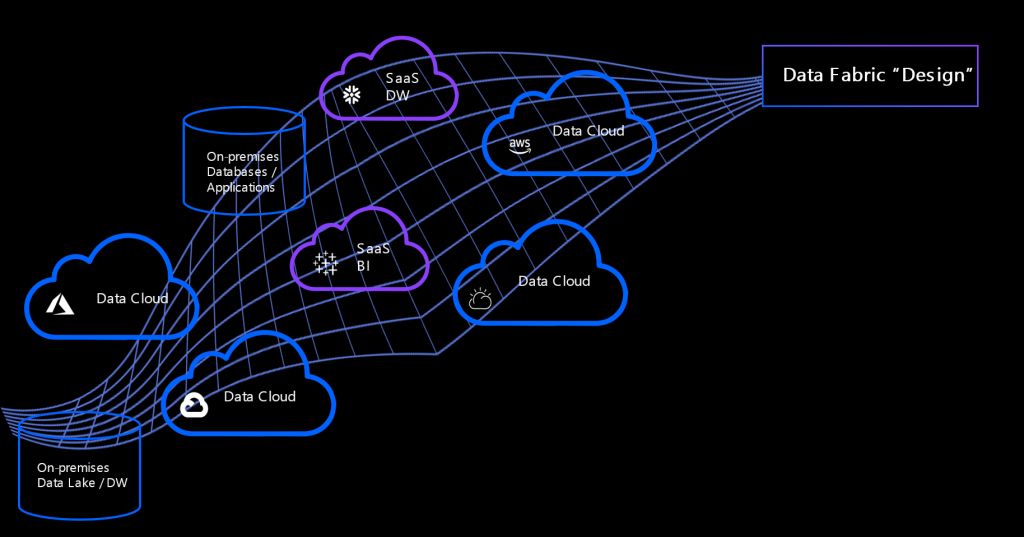
Data fabric architecture
A data fabric could be logically divided into four capabilities (or components):
Knowledge, insights and semantics
- Provides a data marketplace and shopping experience
- Automatically enriches discovered data assets with knowledge and semantics, allowing consumers to find and understand the dana
Unified governance and compliance
- Allows local management and governance of metadata but supports a global unified view and policy enforcement
- Automatically applies policies on data assets in accordance with global and local rules
- Utilizes advanced capabilities to automate data asset classification and curation
- Automatically establishes query able access routes for any cataloged assets for increased activation of data
Intelligent integration
- Accelerates a data engineer’s tasks through automated flow and pipeline creation across distributed data sources
- Enables self-service ingestion and data access over any data with local and global deep enforcement of data protection policies
- Automatically determines best fit execution through optimized workload distribution and self-tuning and correction of schema drifts
Orchestration and lifecycle
- Enables the composition, testing, operation and monitoring of data pipelines
- Infuses AI capabilities in the data lifecycle to automate tasks, self-tune, self-heal and detect source data changes, all of which facilitates automated updates
Applying data fabric architecture avoids excessive data copying and optimizes the way data is moved or accessed. Sometimes we can’t reduce the amount of data or the complexity of a data network, but we can use techniques so that the data is retrieved in the best possible way. Also in this way, a highly automated and guided user experience can be established.

IBM Cloud Pak for Data
IBM Cloud Pak® for Data makes this concept of a data fabric possible. IBM Cloud Pak for Data is an insight platform that simplifies and automates data collection, organization and analysis of data and accelerates the infusion of AI throughout your business.
The greatest value of this system lies in the fact that the complete set of tools and services required for complete data handling is implemented in one integrated platform, making hardware infrastructure costs lower and reducing the time and resources required for implementation and overall maintenance. With its capabilities to connect data everywhere; run workloads anywhere; and to build, deploy and manage AI at scale in hybrid cloud environments, IBM Cloud Pak for Data is the enabler for a business digital transformation.

