Blog
Posluživanje modela strojnog učenja
Cilj ovog bloga je demonstrirati kako poslužiti neki duboki model za klasifikaciju slika. Najpopularnija rješenja za posluživanje modela kroz API su NVIDIA Triton Inference Server, TensorFlow Serving i TorchServe. Kako i samo ime kaže, TensorFlow Serving se koristi za posluživanje modela pisanih u TensorFlowu, a TorchServe za modele pisane u PyTorchu. Za razliku od njih, NVIDIA Triton Inference Server može posluživati modele iz različitih razvojnih okvira.
U svakom primjeru koristit ćemo isti model: MobileNetV2 pretreniran na ImageNet skupu podataka.

NVIDIA Triton Inference Server
Budući da najviše mogućnosti nudi Triton server, s njim ćemo i započeti.
TensorFlow model
Prvo što moramo napraviti je instancirati i serijalizirati MobileNetV2 model. Preporučeni način sa službene dokumentacije je unutar Docker okoline koju je dizajnirala NVIDIA.
Postoji više načina kako ovo postići, mi predlažemo sljedeći Dockerfile:
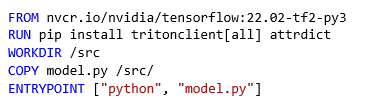
Skripta kojom ćemo to izvršiti je vrlo jednostavna:

Serijalizacija se izvršava unutar Docker okoline u kojoj su instalirane sve potrebne biblioteke:
docker run \
--gpus all \
--rm \
--name nvidiatensorflow \
-v /direktorij/u/koji/ce/se/spremiti/model/:/src/model.savedmodel \
nvidiatensorflowTriton server očekuje da modeli koje će posluživati budu posloženi u specifičnom formatu. Slijedi primjer kako smo to mi napravili za TensorFlow model (i za PyTorch model):
tfmobilenet
├── 1
│ └── model.savedmodel
│ └── serijalizirane datoteke
├── config.pbtxt
└── labels.txt
torchmobilenet
├── 1
│ └── model.pt
├── config.pbtxt
└── labels.txtSada kada smo model serijalizirali u pogodnom formatu, moramo Triton serveru opisati taj model, konkretno, koji su mu ulazi i izlazi, njihove dimenzije i formati. Tome služi datoteka config.pbtxt.
name: "tfmobilenet"
platform: "tensorflow_savedmodel"
max_batch_size: 8
input [
{
name: "input_1"
data_type: TYPE_FP32
dims: [ 224, 224, 3 ]
format: FORMAT_NHWC
}
]
output [
{
name: "predictions"
data_type: TYPE_FP32
dims: [ 1000 ]
label_filename: "labels.txt"
}
]Imena ulaznih i izlaznih tenzora te njihove dimenzije mogu se saznati na više načina:
- prilikom izvođenja skripte model.py pogledati ispis modela, na početku je opisan ulazni tenzor, a na kraju izlazni tenzor, slijedi skraćena verzija ispisa u kojoj su crvenom bojom označena imena ulaznih i izlaznih tenzora,
Model: “mobilenetv2_1.00_224”
Layer (type) Output Shape Param #
============================================================
input_1 (InputLayer) [(None, 224, 224, 3)] 0
...
predictions (Dense) (None, 1000) 1281000
=============================================================
Total params: 3,538,984
Trainable params: 3,504,872
Non-trainable params: 34,112
- nakon što je model sačuvan, moguće je ispisati arhitekturu pomoću alata saved_model_cli, slijedi skraćeni ispis
signature_def['serving_default']:
The given SavedModel SignatureDef contains the following input(s):
inputs['input_1'] tensor_info:
dtype: DT_FLOAT
shape: (-1, 224, 224, 3)
name: serving_default_input_1:0
The given SavedModel SignatureDef contains the following output(s):
outputs['predictions'] tensor_info:
dtype: DT_FLOAT
shape: (-1, 1000)
name: StatefulPartitionedCall:0
Method name is: tensorflow/serving/predictU datoteci labels.txt nalazi se popis svih klasa ImageNet skupa podataka.
Triton server nudi više protokola koji poslužuju metode za inferenciju, a mi ćemo isprobati HTTP protokol. Da ne bismo morali otkrivati i kopati po dokumentaciji i izvornom kodu kako poslati zahtjeve, Triton nudi svoju biblioteku za komuniciranje sa serverom. Uz to, postoji i skripta koja zapakira tu biblioteku i nudi jednostavno sučelje za slanje zahtjeva:
Sada pomoću te skripte možemo poslati zahtjev na Triton server:
python send_request.py kitten.jpg --model-name tfmobilenetOdgovor koji dobijemo sa servera je:
['0.683438', '285', 'Egyptian cat']PyTorch model
Probajmo napraviti istu stvar, ali umjesto TensorFlow modela koristit ćemo PyTtorch model. Prema službenoj dokumentaciji, kao i u TensorFlow slučaju, moramo koristiti Docker image koji je pripremila NVIDIA. Dockerfile će izgledati identično kao za TensorFlow, samo će razlika biti u početnom Docker imageu:

Triton server zahtijeva da se PyTorch modeli serijaliziraju “po TorchScript” načinu. Tada bi serijalizacija MobileNetV2 modela izgledala ovako:

Isto kao za TensoFlow potrebno je tu skriptu pokrenuti u Docker okolini:
docker run \
--gpus all \
--rm \
--name nvidiapytorch \
-v /direktorij/u/koji/ce/se/spremiti/model/:/src/torchmobilenet \
nvidiapytorchSerijalizirani model koji smo dobili pokretanjem ove skripte potrebno je opisati konfiguracijskom datotekom, baš kao u TensorFlow primjeru.
name: "torchmobilenet"
platform: "pytorch_libtorch"
max_batch_size: 8
input {
name: "input__0"
data_type: TYPE_FP32
dims: [3, 224, 224]
format: FORMAT_NCHW
}
output {
name: "output__0"
data_type: TYPE_FP32
dims: [ 1000 ]
label_filename: "labels.txt"
}
default_model_filename: "model.pt"Glavna razlika u odnosu na TensorFlow model jest poredak dimenzija ulaznog tenzora/fotografije. Redoslijed dimenzija u TensorFlow modelu su:
- batch
- visina
- širina
- RGB
U PyTorch modelu redoslijed je nešto drugačiji:
- batch
- RGB
- visina
- širina
Kada pošaljemo zahtjev dobijemo odgovor:
['15.189675', '281', 'tabby']
TorchServe
TorchServe ćemo, kao i TritonServer, pokrenuti unutar prikladne Docker okoline.
TorchServe pruža specijalizirani alat za serijalizaciju modela pomoću kojeg možemo iskoristiti model koji smo prethodno serijalizirali za Triton server. Potrebno je sljedeće:
- direktorij u koji ćemo staviti prethodno serijalizirani PyTorch model,
- datoteka koja definira mapiranje indeksa u ime klase.
Naredba kojom ćemo to postići je:
docker run \
--rm \
-it \
--gpus all \
-v /putanja/do/ulaznog/modela:/home/model-server/inputs \
-v /putanja/do/spremljenog/modela:/home/model-server/model-store \
--name torchserve \
torchserve \
torch-model-archiver \
--model-name mobilenet \
--serialized-file inputs/model.pt \
--handler image_classifier \
--version 1.0 \
--extra-files inputs/index_to_name.json \
--export-path model-storeSada možemo pokrenuti TorchServe:
docker run \
--rm \
-it \
--gpus all \
-v /putanja/do/spremljenog/modela:/home/model-server/model-store \
--name torchserve \
-p 8080:8080 \
torchserve \
torchserve \
--start \
--model-store model-store/ \
--models mobilenet=model-store/mobilenet.marSlanje zahtjeva jednostavnije je nego u Triton slučaju, dovoljan je samo curl:
curl http://localhost:8080/predictions/mobilenet -T examples/cat.jpegDobijemo odgovor sa servera:
{
"tabby": 0.45494621992111206,
"Egyptian_cat": 0.41108807921409607,
"lynx": 0.0843689814209938,
"tiger_cat": 0.0472283735871315,
"leopard": 0.000700850214343518
}TensorFlow Serving
Za TensorFlow Serving možemo iskoristiti isti model koji smo serijalizirali za Triton server. Struktura direktorija je slična onoj koju smo izradili za Triton server.
Postoji više načina kako definirati konfiguraciju modela, od kojih smo mi odabrali konfiguraciju preko konfiguracijske datoteke:

Tu smo definirali ime i putanju do serijalizirane datoteke modela.
Ovako bi trebala izgledati struktura direktorija:
├── models
│ ├── models.conf
│ └── tfmobilenet
│ └── 1
│ └── serijalizirane datoteke
├── models.confOvog puta skriptu za slanje zahtjeva prepuštamo čitatelju pa ćemo staviti samo dio:

Zaključak
Za kraj je bitno reći da svi ovi alati koliko imaju benefita toliko imaju i (neočekivanih) mana. U ovom smo blogu posluživali jedan od jednostavnijih modela u području klasifikacije slika. Međutim, postoje daleko složeniji modeli koji vrlo vjerojatno neće raditi iz prve. Kako biste si omogućili što više opcija u posluživanju takvih modela preporučamo pobliže upoznavanje sa svakim od navedenih alata.

