Blog
Primjena YOLO algoritma računalnog vida
YOLO algoritam (engl. You Only Look Once) samim imenom naslućuje da se radi o algoritmu iz podskupine “One-Stage” algoritama računalnog vida. Jedno-razinsku skupinu dijeli zajedno sa SSD (engl. Single Shot Detection) algoritmom koji je nešto precizniji od YOLO algoritma, ali i sporiji. Upravo je brzina i primjena u realnom vremenu glavna prednost i karakteristika YOLO algoritma.
Drugi algoritmi kao što su popularni Fast-RCNN i Faster-RCNN, spadaju u skupinu “Two-Stage” algoritama, gdje se na prvoj razini odvija detekcija mogućih regija s objektima na slici, a na drugoj klasifikacija u tim regijama. Upravo potreba za odvijanjem više iteracija u istoj slici znatno usporava te algoritme, iako im daje prednost u pouzdanosti rezultata.
Način rada YOLO algoritma
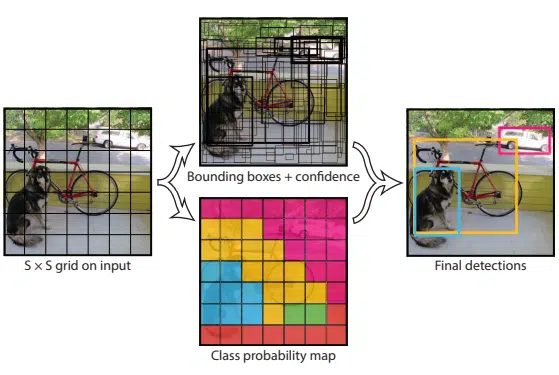
Osnova rada YOLO algoritma je što se sve predikcije na jednoj slici odvijaju odjednom pomoću jedinstvenog potpuno povezanog sloja. Postupak predikcije može se opisati s tri ključna koraka:
- ravnomjerna podjela slike u N ćelija, od kojih svaka ima jednaku SxS dimenziju,
- predikcija “bounding box” koordinata unutar svake ćelije za svaki objekt, njegova klasifikacija, te vjerojatnost da se taj objekt nalazi u toj ćeliji,
- NMS (engl. Non Maximal Suppression) za filtraciju “bounding box” regija kako bi ostala samo jedna za pojedini objekt s najvećim rezultatom pouzdanosti klase objekta.
Ključna razlika između SSD i YOLO algoritma je način regresije “bounding-box” regija. U navedenom trećem koraku YOLO algoritma (NMS), regresija “bounding-box” regija odvija se tako da se za preklapajuće regije provjerava jesu li klase objekata u njima iste ili različite. IoU principom (engl. Intersection Over Union) određuje se koliko se u postotku regije preklapaju za istu klasu objekta. Za preklapanje iznad 50%, one regije koje su višak se eliminiraju. Za lokaciju objekta odabire se težišna točka regije s prosječnim rezultatom.
Razvoj YOLO algoritma
Osnovna verzija YOLO algoritma iz 2015. godine imala je problem s detekcijom manjih grupiranih objekata, te s preciznošću njihove lokalizacije. Iduće godine izlazi YOLOv2 algoritam koji uvodi primjenu “anchor-box” regija. Dok je osnovni algoritam koristio fiksnu SxS mrežu gdje je svaka ćelija predviđala samo jednu klasu objekta, uvođenjem “anchor-box” regija za predikciju omogućeno je predviđanje više “bounding-box” regija za svaku ćeliju u SxS mreži. Time je riješen problem malih objekata različitih klasa koji se nalaze unutar jedne ćelije.
Idući korak u razvoju je bio YOLO9000 algoritam koji je za cilj imao proširenje mogućih klasa za detekciju, odnosno s 80 klasa COCO dataseta na 22000 ImageNet dataseta. Kako su se neke klase iz COCO dataseta hijerarhijski preklapale s onima iz ImageNet-a, rezultat je bio negdje preko 9000 mogućih klasa za detekciju, s tim da se snizila prosječna preciznost predikcije.
YOLOv3 za novitet uvodi kao osnovu arhitekture mreže DarkNet-53, složeniji model od DarkNet-19 koji se koristio na prethodnoj verziji. Također, svaka ćelija predviđa tri “bounding-box” regije, od kojih svaka radi dodatnu predikciju u tri različite skale objekta, što dovodi do ukupno devet “anchor-box” regija po ćeliji.
Daljnji razvoj YOLO algoritama odvijao se na “open-source” razini, s tim da je najnovija verzija YOLOv7 (2022).
Primjena i usporedba YOLOv3 i YOLOv5 algoritama na detekciji polica u trgovini
YOLOv3 je izašao 2018. godine i imajući u vidu da ima dobro utvrđenu bazu, bilo je lako pripremiti našu bazu podataka i istrenirati model da prepoznaje police u trgovini. YOLOv3 kao glavnu prednost ima znatno brže vrijeme inferencije u odnosu na druge popularne modele, ali ne zaostaje puno ni s prosječnom preciznošću.
Inferencijom istreniranog modela na nekoliko testnih fotografija dobiveni su rezultati prikazani na slici 3.

Iako je YOLOv3 dao iznimno zadovoljavajuće rezultate na setu od 250 testnih slika, s vrlo malim udjelom lažno pozitivnih rezultata, isprobali smo i YOLOv5. Glavna prednost YOLOv5 verzije u odnosu na YOLOv3 je brzina treniranja i inferencije, dok bi prosječna preciznost trebala biti manje-više ista. Nakon treniranja dobiveni su rezultati prikazani na slici 4.

Zaključak
Na temelju pročitanih radova koji detaljno opisuju i uspoređuju performanse YOLO algoritama, došli smo do izbora između dva provjerena algoritma s opširnim bazama znanja, a to su YOLOv3 i YOLOv5. Iako nam je u fokusu više bila pouzdanost i preciznost rezultata nego vrijeme izvršavanja inferencije, što je glavna prednost svih YOLO algoritama, oba algoritma su se pokazala kao dobar izbor. Ukupno vrijeme inferencije nešto je kraće s YOLOv5 modelom, ali se pokazalo da u slučaju prepoznavanja polica ipak ima tendenciju dati lažno pozitivne rezultate, dok je YOLOv3 uz nešto niže pouzdanosti predikcije ipak davao točnije rezultate.
Kao i sa svim drugim algoritmima računalnog vida, uslijed raznih nepredvidivih faktora u realnoj primjeni (svjetlosni uvjeti, ljudski utjecaj), ne postoji ni jedan savršeni model za svaki problem, pa tako ni za problem detekcije polica u trgovini. Promatrajući probleme u širem kontekstu, moramo odvagati što će u konačnici rezultirati zadovoljstvom korisnika, jer algoritam računalnog vida je samo jedan dio cjeline, odnosno naše aplikacije.
Reference:
https://www.v7labs.com/blog/yolo-object-detection#h2
https://algoscale.com/blog/yolo-vs-ssd-which-one-is-a-superior-algorithm/

