Blog
Računalni vid ide u trgovinu
Postoje procjene po kojima se 76% svih odluka pri kupovini donosi na licu mjesta. Iz toga se može pretpostaviti da je većina kupovina impulzivne prirode. Na tu pretpostavku se oslanjaju proizvođači i distributeri i ulažu resurse u razvoj procesa u tom krajnjem koraku prodaje.Optimizacija tih procesa u svrhu maksimiziranja prodaje zove se retail execution, a najčešće se spominje u kontekstu proizvoda široke potrošnje (FMCG – Fast Moving Consumer Goods ili CPG – Consumer Packaged Goods).
Postoji nekoliko problema čijim se rješavanjem poboljšava retail execution:
- prepoznavanje proizvoda koji nedostaju na polici (out-of-stock),
- praćenje udjela proizvoda u odnosu na konkurenciju i
- kontroliranje usklađenosti s planogramom.
Prepoznavanje proizvoda koji nedostaju na polici (out-of-stock)
Proizvođači i distributeri izrazito moraju voditi brigu o tome da trgovina koja stavlja njihov proizvod na tržište redovito obnavlja zalihe na policama, inače to predstavlja gubitke u prodaji. Recimo da ste došli u trgovinu kupiti svoje najdraže bezalkoholno gazirano piće, a tog pića više nema na polici. U tom slučaju ćete se vjerojatno odlučiti za drugo najdraže, što bi moglo biti piće konkurentnog proizvođača. Naravno, briga o zalihama proizvoda na polici ne povjerava se isključivo trgovini. Proizvođači i distributeri često šalju svoje zaposlenike na teren kako bi osigurali da se takvi slučajevi što manje događaju.
Praćenje udjela proizvoda (u odnosu na konkurenciju)
Jedna od češćih metrika koju promatraju proizvođači i distributeri je udio vlastitog proizvoda u odnosu na konkurenciju na polici – shelf share. Kada kao proizvođač stavljate svoj proizvod na tržište (u ovom su to slučaju police u trgovinama), s trgovinama dogovarate na kojim mjestima će se nalaziti vaš proizvod i koliki udio će zauzimati. Budući da su police organizirane tako da sadrže proizvode iste kategorije, vaš se proizvod nalazi “bok uz bok” s konkurencijom. Trenutni način na koji se provjerava drže li se trgovine dogovorenog udjela sličan je onome u rješavanju out-of-stock problema – šalju svoje zaposlenike na teren kako bi na polici ručno izbrojali vlastite proizvode i proizvode konkurencije.
Kontroliranje usklađenosti s planogramom
Za razliku od praćenja udjela, gdje je fokus stavljen na usporedbu s konkurencijom, kontroliranje planograma odnosi se prvenstveno na pozicioniranje vlastitih proizvoda. Planogram je detaljna vizualna reprezentacija rasporeda proizvoda na polici u trgovini. Proizvođači zakupljuju određen broj lica (mjesto koje zauzima jedan proizvod) na svakoj polici. Koliko je lica i koji su proizvodi u pitanju definirano je planogramom. Budući da je raspored proizvoda visoko optimiziran za maksimizaciju prodaje, bilo kakvo odstupanje od dogovorenog rasporeda predstavlja potencijalne gubitke. Kao što je i prije spomenuto, svi ovi problemi rješavaju se ručno, točnije rečeno, agenti na terenu stanu ispred police i broje jedan po jedan artikl.
Kada bi se prethodno spomenuti problemi uspjeli automatizirati barem do neke mjere, ovo bi bili pozitivni ishodi:
- značajna ušteda vremena i resursa – agenti na terenu efikasnije bi analizirali stanje na policama,
- precizniji podaci – smanjila bi se ljudske pogreške, te
- instantni i češći uvid u stvarno stanje na terenu.
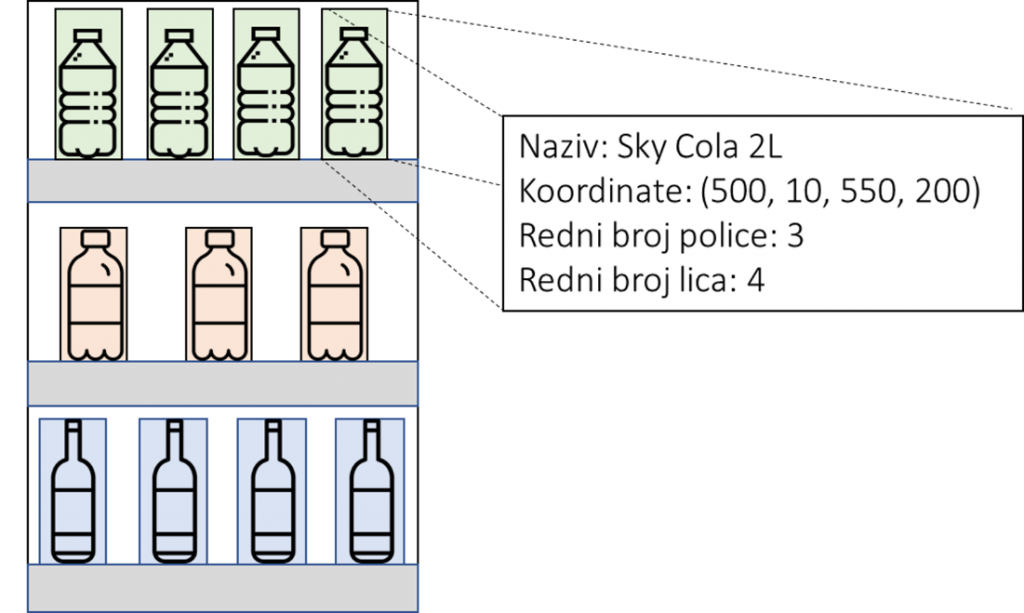
Upravo su to problemi koje rješavamo u sklopu projekta SOVA. Rješenje koje istražujemo i razvijamo bazirano je na računalnom vidu potpomognutom umjetnom inteligencijom. Na temelju jedne fotografije naš alat u stvarnom vremenu može pružiti sljedeće informacije:
- koordinate svakog artikla/proizvoda na policama,
- naziv svakog artikla,
- redni broj police na kojoj se artikl nalazi,
- redni broj lica u polici (redni broj artikla gledano slijeva na desno) kao i
- veličinu ambalaže.
Projekt SOVA
Pojmovi koji se češće koriste u području umjetne inteligencije za predviđanje koordinata i naziva artikala su detekcija i klasifikacija. Matematički modeli koje koristimo za obavljanje tih zadataka su duboke neuronske mreže. Poznato je da su za takve modele najbitniji podaci na kojima će se ti modeli učiti/trenirati. To znači da je potrebno imati veliku količinu fotografija te za svaku fotografiju zabilježene informacije o koordinatama artikala i imenima. Prikupljanje takvog skupa podataka poprilično je zahtjevan proces prvenstveno zato što je potrebna ljudska snaga koja će označiti te informacije na svakoj fotografiji. Ukratko, nije nimalo jednostavno imati znanost o podacima bez podataka.
Još jedan od izazova koji je neizbježan je proširivanje asortimana. Počeli smo istraživanje i razvoj sa svega 10 različitih artikala u kategoriji gaziranih pića. Od početka našeg projekta broj artikala koji su ubačeni u sustav popeo se na približno 1.000. Kategorije koje smo pokrili dosad su gazirana pića, ledeni čajevi, sokovi u prahu, paštete, mesni naresci i kave. Na tom istraživačkom putu pročitali smo brojne radove iz akademije i implementirali mnoge ideje. Kako sada izgleda obrada fotografije i koji su rezultati možete vidjeti na sljedećim slikama.



Sa svim tim podacima i znanjem uspješno smo savladali navedene izazove, a neki koje planiramo za budućnost su:
- predviđanje orijentacije proizvoda (npr. zaokrenutost boce),
- čitanje cijena,
- uparivanje proizvoda s njihovim cijenama i
- generiranje 3D scena koje predstavljaju police u trgovinama.
Bitno je ne izostaviti izazov koji je sveprisutan: kontinuirano poboljšanje svih dosadašnjih rješenja.
Poslovne ambicije projekta su takve da planiramo pokriti što veći asortiman proizvoda u trgovinama za robu široke potrošnje. Time će nam se otvoriti putevi za pristup kako domaćem tako i međunarodnom tržištu. Naravno, kroz vrijeme očekujemo da će nam se otvoriti potpuno novi izazovi odnosno nova područja istraživanja i razvoja.

