Blog
Sve što trebate znati za izradu svog prvog web scrapera
Kako količina na webu dostupnih informacija raste te informacije postaju sve vrjednije, područje automatiziranog sustavnog pretraživanja weba dobiva sve veću važnost. Više informacija i bolje informacije od iznimne su važnosti za donošenje poslovnih odluka, zbog čega je korisno znati kako automatizirano doći do većih količina informacija na Internetu te kako izvući i obraditi tražene informacije.
Što je to web scraping?
Dva glavna pojma u području ekstrakcije web sadržaja su web scraping i web crawling. Web scraping jest sistematizirana ekstrakcija tekstualnog ili medijskog sadržaja s web stranica, postignuta korištenjem alata zvanih web scraperi. Koncept web scrapinga temelji se na korištenju metoda web crawlinga, automatiziranog sustavnog pretraživanja weba postignutog praćenjem poveznica web stranica pomoću web crawlera. Procesi web scrapinga i web crawlinga čine kontinuirani ciklus: crawlingom dolazimo do HTML dokumenata iza web stranica, iz kojih izvlačimo željeni sadržaj i poveznice na ostale web stranice pomoću scrapinga, te dalje vršimo crawling po prikupljenim poveznicama.
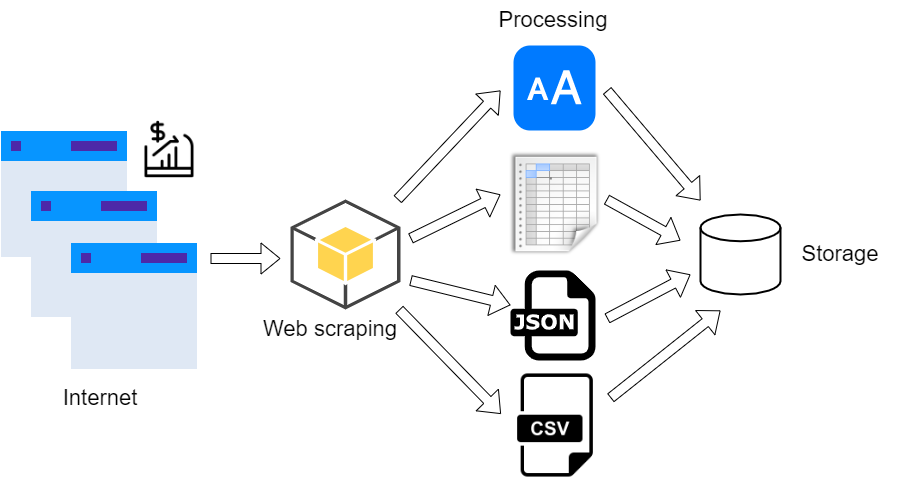
Zašto web scraping? Poduzećima web scraping pomaže na mnogo načina. Najčešće je riječ o analizi kompetitivnosti cijena i motrenju konkurencije, te istraživanju tržišnih scenarija (trendova) prije plasiranja usluge ili proizvoda na tržište. Osim toga, dodatni agregirani podaci s weba uvijek dobro dođu i u raznim područjima umjetne inteligencije i znanosti o podacima.
Pristojnost crawlinga
Kada radimo crawling po webu, poželjno je poznavanje četiri osnovne politike rada:
- Politika selekcije: koje stranice preuzeti?
- Politika ponovnog posjeta: kada provjeravati za promjene na stranicama?
- Politika pristojnosti: kako izbjeći preopterećenje web stranica?
- Politika paralelizacije: kako koordinirati distribuirane web crawlere?
Očigledno najbitnija politika je politika pristojnosti, kod koje je pitanje kako ne biti prevelik teret poslužiteljima stranica koje pretražujemo. Postoji nekoliko mehanizama koji pomažu pri rješavanju tog problema:
- User Agent (korisnički agent), string za identifikaciju poslužitelju (pristojni crawleri ostavljaju mail adresu ili URL adresu za kontakt u slučaju problema)
- najbitniji je ipak datoteka robots.txt na određenom poslužitelju, koja daje crawlerima pravila koje stranice smiju, odnosno ne smiju pretraživati, te koliko bi trebali čekati između svaka dva posjeta stranicama na poslužitelju
neke robots.txt datoteke imaju i poveznicu na dodatnu, tzv. sitemap datoteku, koja sadrži listu svih dopuštenih URL adresa, a često i njihovu prioritetnost za indeksiranje (koliko je sadržaj na određenoj stranici relevantan).
Predznanja i alati
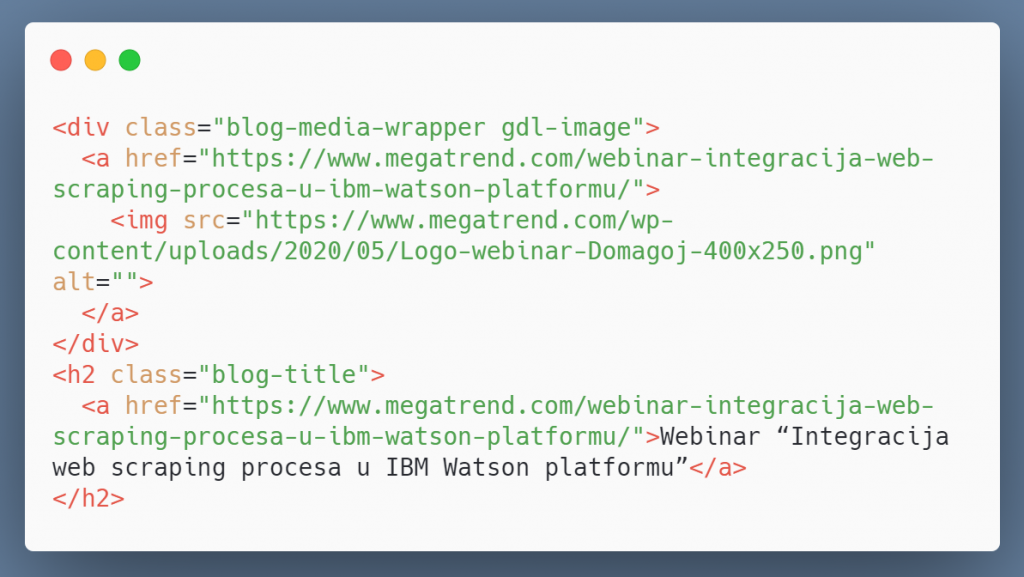
Prije početka rada na web scraperima poželjno je imati dobro pozadinsko znanje o HTTP protokolu (tipovi zahtjeva i status kodovi) te tipičnoj strukturi HTML dokumenata, što su tagovi (oznake), koji tagovi imaju koje atribute, što su id i class tagova i slično. Jednako bitno je i poznavanje raznih selektora koji mogu poslužiti za navigaciju kroz takvu strukturu, poput XPath i CSS selektora. Osim navedenih selektora u praksi se koriste i regularni izrazi, sekvence znakova koje označavaju veću skupinu drugih sekvenci znakova, korisne za pronalaženje specifičnog sadržaja unutar strukture HTML dokumenta.
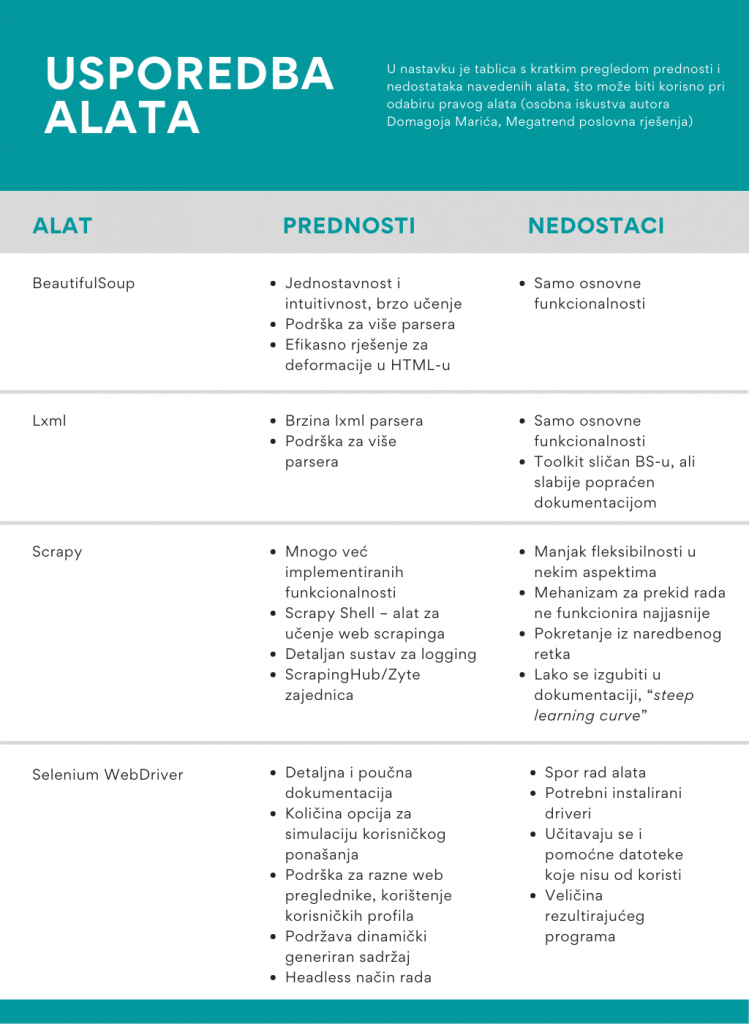
Najčešći izbor za programiranje vlastitog scrapera je programski jezik Python zbog njegove jednostavnosti obrade tekstualnih podataka. Neki popularniji Python alati su:
- Requests: HTTP zahtjevi za web stranicama (odnosno HTML dokumentima)
- BeautifulSoup i lxml: parseri HTML datoteka, popularni zbog jednostavnosti i brzine razvoja skripti
- Scrapy: razne naprednije, već implementirane funkcionalnosti, uključujući i vrlo koristan Scrapy Shell za učenje
- Selenium WebDriver: simulacija ljudskog ponašanja u pretraživanju dinamičnih stranica, primjerice klikova i klizanja mišem te unosa teksta u polje

Ako imate bilo kakvih pitanja oko web scrapinga i/ili web crawlinga, bila ona vezana za tehničku izvedbu ili za upite oko njihove korisnosti u poslovnim procesima, slobodno se javite na domagoj.maric@megatrend.com.

