Blog ENG
All you need to know to make your first web scraper
As the amount of information available on the web grows and the information becomes more valuable, the field of automated systematic web browsing is becoming increasingly important. More information and better information is extremely important for making good business decisions, which is why it is useful to know how to automatically access larger amounts of information on the Internet and how to extract and process the information you are looking for.
What is web scraping?
The two main concepts in the field of web content extraction are web scraping and web crawling. Web scraping is the systematic extraction of text or media content from web pages, achieved through the use of tools called web scrapers. The concept of web scraping is based on the use of web crawling methods, automated systematic web browsing achieved by tracking website links using web crawlers.
The processes of web scraping and web crawling form a continuous cycle: crawling leads to the HTML documents behind web pages, from which we extract the desired content and links to other web pages using scraping, and then crawl the collected links.
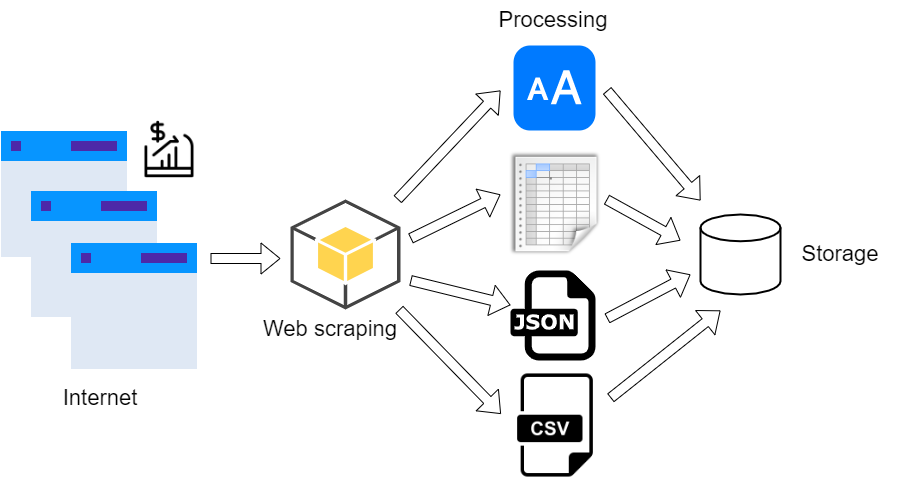
Why web scraping? Web scraping helps businesses in many ways. Most often, it is used for analysis of price competitiveness, monitoring of competition, and research of market scenarios (trends) before placing a service or product on the market. Moreover, additional amounts of aggregated data from the web are always welcome in various fields of artificial intelligence and data science.
FIGURE 1:
Applications of web scraping:
Price competitiveness
- Competition monitoring
- Price extraction to gain market advantage
Research of market scenarios (trends)
- Brand monitoring
- Planning to launch a new product or service on the market
- Trademark infringement detection
Sentiment analysis
- Online reputation management
- Monitoring consumer reactions by extracting ratings, reviews and feedback on forums and social networks
Human resources
- The selection and recruiting process
- Job ad extraction
Content aggregation
- Extraction and further processing into organized knowledge bases
Crawling politeness
When we are crawling the web, it is crucial to know the four basic crawling policies:
- Selection policy: which pages to download?
- Re-visit policy: when to check for changes to the pages?
- Politeness policy: how to avoid overloading web sites/servers?
- Parallelization policy: how to coordinate distributed web crawlers?
Obviously the most important policy is the politeness policy, where the question is how not to be too much of a burden to the servers of the pages we crawl. There are several mechanisms that help us solve this problem:
- the User Agent, a string used for the identification to the server (polite crawlers leave behind a mail address or URL address as contact info in case of a problem)
- the most important mechanism is the robots.txt file, located on the server, which gives crawlers rules on which pages they are allowed, or not allowed to crawl, as well as how long they should wait in between two consecutive visits to the server
- some robots.txt files also have a link to an additional, sitemap file, which contains a list of all allowed URL addressed, and often their priority for indexing (how relevant the content on a certain site is)
Knowledge prerequisites and tools
Before starting to work on web scrapers, it is nice to have a good background knowledge of the HTTP protocol (request types and status codes) and the typical structure of HTML documents, what tags are, which tags contain which attributes, what id and class tags are etc. It is equally important to know the various selectors that can be used to navigate through such a structure, such as XPath and CSS selectors. In addition to these selectors, in practice we also use regular expressions (regex), sequences of characters that denote a larger group of other sequences of characters, useful for finding specific content within the structure of an HTML document.
The most common language choice for programming your own web scraper is the Python programming language because of its ease of processing text data. Some more popular Python tools are:
- Requests: HTTP requests for web pages (i.e. HTML documents)
- BeautifulSoup and lxml: HTML document parsers, popular for their simplicity and speed of script development
- Scrapy: various advanced, already implemented functionalities, including the very useful Scrapy Shell for learning how to use selectors
- Selenium WebDriver: simulation of human behavior in browsing dynamic pages, such as mouse clicks and scrolls, entry of text in fields, etc.
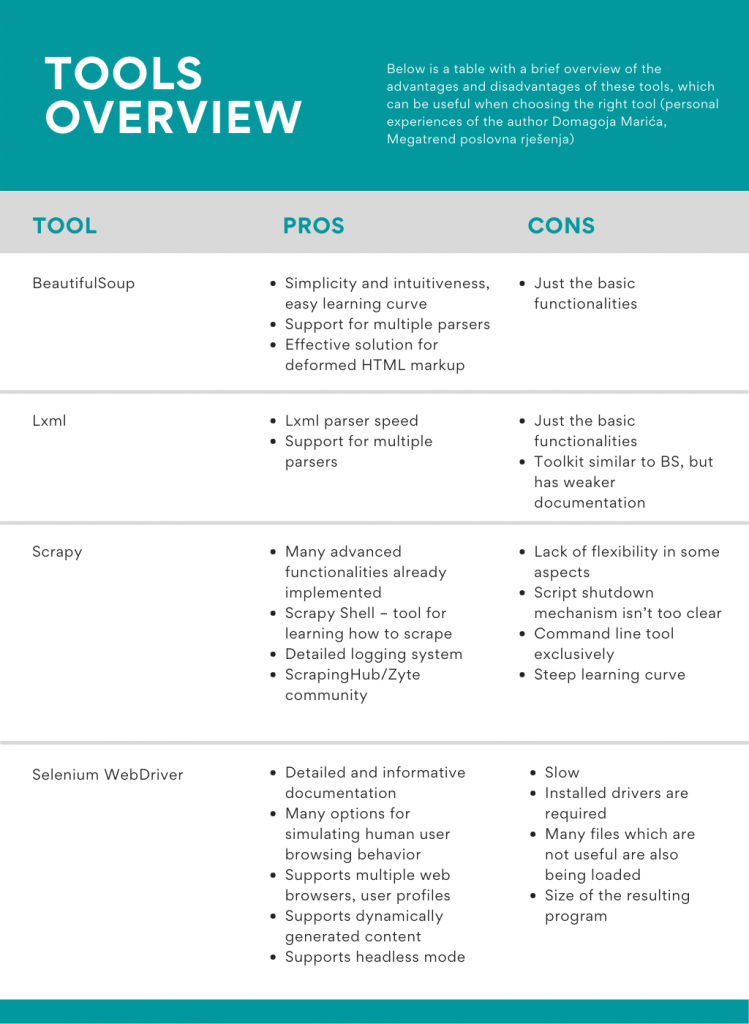
Below is a table with a brief overview of the advantages and disadvantages of these tools, which can be useful when choosing the right tool (personal experiences of the author).

If you have any questions or would like to discuss web scraping/crawling (whether regarding the technical implementation or business applications), feel free to contact the author of this post at domagoj.maric@megatrend.com.

