Blog
Verzioniranje podataka pomoću DVC-a
Uvod
Većina programera se kroz projekte susrela sa sustavom za verzioniranje izvornog koda – Git, ali teže je pitanje kako upravljati (velikim) datotekama kojima Git ne prati verziju? U ovom blogu ćemo vas upoznati sa sustavom za verzioniranje podataka DVC (engl. Data Version Control). DVC omogućava praćenje verzija datoteka te njihovu pohranu u cloudu. Na taj način vi i vaš tim u svakome trenutku možete koristiti trenutne i prethodne verzije tih datoteka. Također, u drugome dijelu bloga prikazat ćemo kako se pomoću DVC-a mogu izbjeći nepotrebna izvođenja pojedinih dijelova bilo kakvog “data driven” pipelinea.
Verzioniranje skupa podataka i modela strojnoga učenja
U ovome dijelu ćemo vas upoznati s osnovnim naredbama DVC-a te pokazati kako možete verzionirati skup podataka i modele strojnoga učenja.
Prvo je potrebno preuzeti Git repozitorij, stvoriti virtualno okruženje, instalirati potrebne biblioteke te inicijalizirati DVC:
git clone git@github.com:robijam/dvc_tutorial.git
cd dvc_tutorial
python3 -m venv .env
source .env/bin/activate
pip install -r requirements.txt
dvc initSljedeća naredba pokreće treniranje jednostavnog modela:
python src/train.py --train-path data/dataset.csvU data direktoriju sada se nalazi skup podataka dataset.csv i model model.pkl.
Kako bi DVC počeo pratiti verziju datoteka model.pkl i dataset.csv, potrebno je izvršiti sljedeće naredbe:
git rm -r --cached 'data/dataset.csv'
git commit -m "stop tracking data/dataset.csv"
dvc add data/model.pkl data/dataset.csvDVC će zatim stvoriti datoteke data/dataset.csv.dvc i data/model.pkl.dvc. U datoteku model.pkl.dvc bit će zapisan MD5 sažetak, veličina i putanja do datoteke model.pkl. Na isti način bit će formirana datoteka dataset.csv.dvc za dataset.csv.

Kako model.pkl i dataset.csv ne bi bili dodani u Git, DVC će stvoriti data/.gitignore s datotekama “/model.pkl” i “/data.csv“.
git add data/model.pkl.dvc data/dataset.csv.dvc data/.gitignoreZatim je potrebno definirati gdje će datoteke koje želimo pratiti pomoću DVC-a biti pohranjene. DVC podržava veliki broj tipova pohrane, a neki od njih su: Amazon S3, SSH, Google Drive, Azure Blob Storage, HDFS. U ovome blogu koristit ćemo Google Drive za pohranu podataka. Kako biste nastavili aktivno pratiti blog, potrebno je u vlastitom Google Drive-u napraviti novi direktorij (npr. dvc_tutorial) te se pozicionirati u njega. Potrebno je kopirati zadnji dio URL adrese kako je prikazano na slici i izvršiti sljedeću naredbu:
dvc remote add -d storage gdrive://vaš_kraj_url_adrese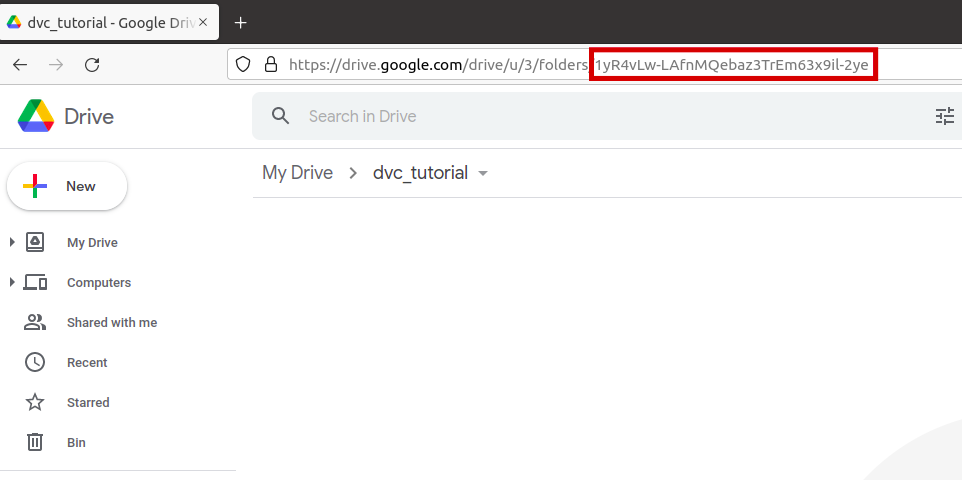
Pohrana datoteka koje prati DVC obavlja se izvršavanjem naredbe dvc push, a dohvat datoteke naredbom dvc pull. Prilikom prvog push-a u Google Drive, bit će potrebno verificirati korisnički račun.

Napomena: ako Git repozitorij koristi više osoba, potrebno je svima dati dopuštenje za korištenje direktorija u vašem Google Drive-u (Desni klik na direktorij -> Share -> Add people and groups).
Te na kraju dodati promjene u Git:
git add .dvc/config
git commit -m "Configure remote storage"Pokrenimo sada skriptu train.py s drugim argumentima:
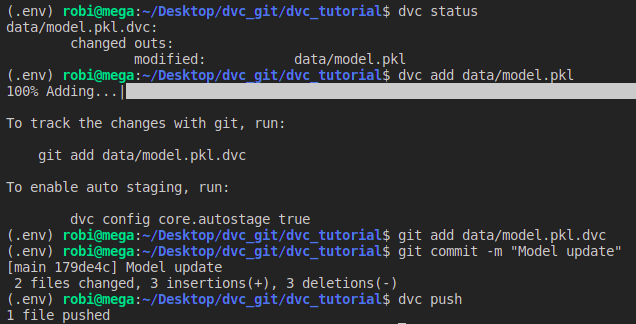
python src/train.py --train-path data/dataset.csv --n-estimators 50Koristeći naredbu dvc status možete provjeriti je li se neka od datoteka koje pratite pomoću DVC-a promijenila. Na primjeru na slici, došlo je do izmjene datoteke model.pkl.
Potrebno je ponovo izvršiti naredbu dvc add kako biste ažurirali datoteku na najnoviju verziju te pomoću naredbe dvc push pohraniti promjene u Drive-u. Osim toga, potrebno je i u Git-u zabilježiti promjene.
Što ako smo shvatili da nam se ipak ne sviđa nova verzija modela i htjeli bismo se vratiti na prethodnu verziju? Nema problema, prvo je potrebno napraviti git checkout datoteke model.pkl.dvc na prethodnu te zatim izvršiti dvc checkout kako bismo izmijenili verziju modela.
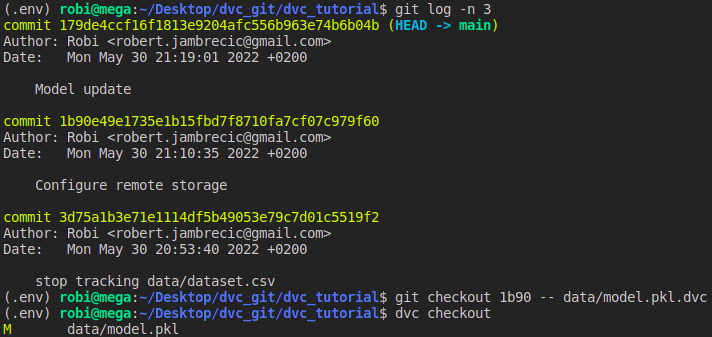
Na isti način možemo koristiti DVC za rad u različitim granama (engl. branch). Npr. imamo dvije grane te u svakoj koristimo različiti skup podataka i različiti model. Nakon što promijenimo granu, potrebno je izvršiti samo dvc checkout kako bismo se prebacili na željenu verziju podataka. Sve verzije koje smo u jednom trenutku preuzeli bit će pohranjene u cacheu tako da će prijelaz s jedne na drugu verziju biti izuzeto brz.
DVC pipelines
U trenutnom projektu imamo sljedeću strukturu.
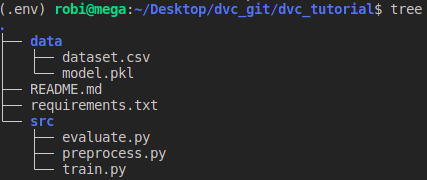
Uobičajen tijek izrade modela strojnoga učenja bio bi preprocess -> train -> evaluate.
- preprocess.py – uzima skup podataka data/dataset.csv te kreira pročišćeni skup podataka za treniranje data/dataset_train_preprocessed.csv i skup podataka za testiranje data/dataset_test_preprocessed.csv
- train.py – trenira model koristeći skup podataka za treniranje te istrenirani model sprema u data/model.pkl
- evaluate.py – testira model na skupu za testiranje i stvara datoteku s metrikama data/evaluate.csv
U ovakvom primjeru možemo koristiti DVC pipeline te definirati u kojem slučaju će se koja faza pokrenuti. Pipeline faza se definira pomoću dvc run naredbe, -n označava ime faze, -d datoteke o kojima ta faza ovisi, -o izlaznu datoteku te -M izlaznu datoteku u kojoj su definirane metrike.
Prije nego što krenemo, potrebno je izbaciti verzioniranje datoteka dataset.csv i model.pkl iz prethodnog primjera:
dvc remove data/model.pkl.dvc data/dataset.csv.dvc
git add data/model.pkl.dvc data/dataset.csv.dvc
git commit -m "Remove dataset.csv and model.pkl versioning"Preprocess faza ovisi o skripti preprocess.py i dataset.csv. U slučaju da dođe do izmjene neke od tih dviju datoteka, pokrenut će se naredba python src/preprocess.py
dvc run -n preprocess \
-d src/preprocess.py -d data/dataset.csv \
-o data/dataset_train_preprocessed.csv -o data/dataset_test_preprocessed.csv \
python src/preprocess.py Train faza ovisi izravno o src/train.py i data/dataset_train_preprocessed.csv te neizravno o src/preprocess.py i data/dataset.csv. U slučaju da dođe do izmjene neke od tih četiriju datoteka, pokrenut će se naredba python src/train.py
dvc run -n train \
-d src/train.py -d data/dataset_train_preprocessed.csv \
-o data/model.pkl \
python src/train.pyEvaluate faza ovisi izravno o src/evaluate.py i data/dataset_test_preprocessed.csv te neizravno o src/preprocess.py, data/dataset.csv i data/model.pkl. U slučaju da dođe do izmjene neke od tih pet datoteka, pokrenut će se naredba python src/evaluate.py
dvc run -n evaluate \
-d src/evaluate.py -d data/dataset_test_preprocessed.csv -d data/model.pkl \
-M data/evaluate.csv \
python src/evaluate.pyNakon izvođenja prethodnih triju naredbi, kreirat će se datoteke dvc.yaml i dvc.lock. Datoteka dvc.yaml definira sve faze pipelinea te za svaku od njih definira: naredbu pokretanja, ovisnosti i izlazne datoteke.
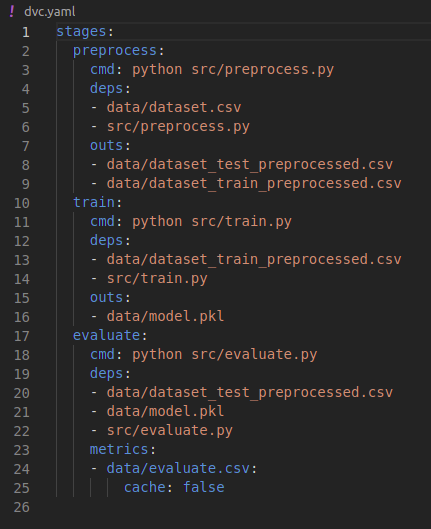
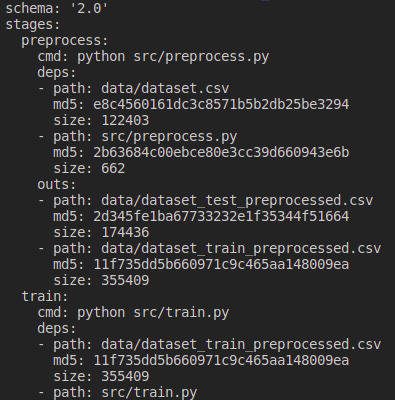
Datoteka dvc.lock definira verzije svih datoteka koje su bile korištene pri posljednjem pokretanju pipelinea.
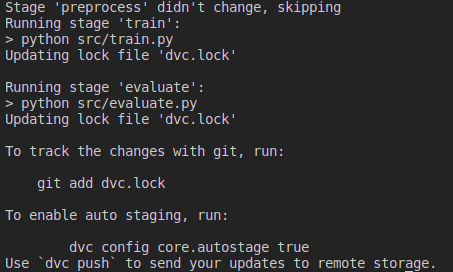
Pomoću naredbe dvc repro pokreću se sve faze kod kojih su se datoteke o kojima ta faza ovisi promijenile od posljednjeg izvođenja (tj. MD5 sažetak tih datoteka se promijenio).
Ako bez ikakve promjene datoteka pokrenemo dvc repro, niti jedna faza neće biti izvršena.

Ako u skripti train.py npr. promijenimo model, pokrenut će se train i evaluate faza.
Zaključak
U ovom smo blogu pokazali kako pomoću DVC-a možete verzionirati podatke unutar Git projekta. Umjesto stvaranja “backup” datoteka prije bilo kakve promjene, možete prepustiti DVC-u da odradi taj posao, a vi se u svakom trenutku možete vratiti na željenu verziju. Također, DVC može ubrzati vaš “data driven” pipeline na način da izvršava samo faze u kojima je došlo do promjene.

