Blog ENG
Versioning data using DVC
Introduction
Most developers have come across a source code versioning system – Git, but how do you manage (large) files that Git doesn’t keep track of? In this blog, we will introduce you to the open source version control system DVC (Data Version Control). DVC allows you to track file versions and store them in the cloud. This way you and your team can use current and previous versions of these files at any time. Also, in the second part of the blog, we will demonstrate how unnecessary runs of certain parts of any “data driven” pipeline can be avoided with the help of DVC.
Versioning of data sets and machine learning models
In this section, we will introduce you to the basic DVC commands and show how you can version data sets and machine learning models.
You first need to download the Git repository, create a virtual environment, install the necessary libraries and initialize the DVC:
git clone git@github.com:robijam/dvc_tutorial.git
cd dvc_tutorial
python3 -m venv .env
source .env/bin/activate
pip install -r requirements.txt
dvc initThe following command starts the training of a simple model:
python src/train.py --train-path data/dataset.csvThe data directory now contains the data set dataset.csv and model model.pkl.
In order for the DVC to start tracking the version of model.pkl and dataset.csv files, the following commands need to be executed:
git rm -r --cached 'data/dataset.csv'
git commit -m "stop tracking data/dataset.csv"
dvc add data/model.pkl data/dataset.csvThe DVC will then create the data/dataset.csv.dvc and data/model.pkl.dvc files. The MD5 summary, size, and path to the model.pkl file will be written to the model.pkl.dvc file. The dataset.csv.dvc file for dataset.csv will be formed in the same way.

To prevent model.pkl and dataset.csv from being added to Git, DVC will create data/.gitignore with the content “/model.pkl” and “/data.csv” written inside.
git add data/model.pkl.dvc data/dataset.csv.dvc data/.gitignoreWe then need to define where the files that we are tracking using the DVC will be stored. DVC supports a large number of storage types, and some of them are: Amazon S3, SSH, Google Drive, Azure Blob Storage, HDFS. In this blog, we will use Google Drive to store data. In order to continue actively following this blog, you need to create a new directory (e.g. dvc_tutorial) in your own Google Drive and to position yourself in it. The last part of the URL address has to be copied as shown in the picture below and the following command executed:
dvc remote add -d storage gdrive://end_of_the_url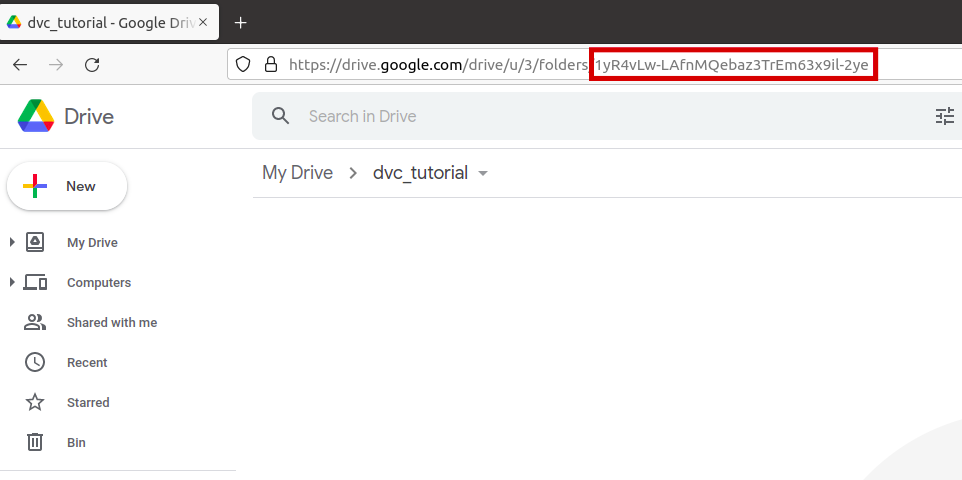
The storage of files tracked by DVC is performed by executing the dvc push command, and file retrieval with the dvc pull command. The first time you push to Google Drive, you will need to verify your account.

Note: If the Git repository is used by more than one person, everyone must be given permission to use the directory in your Google Drive (Right click on the directory -> Share -> Add people and groups).
And finally add changes to Git:
git add .dvc/config
git commit -m "Configure remote storage"Let’s now run the train.py script with other arguments:
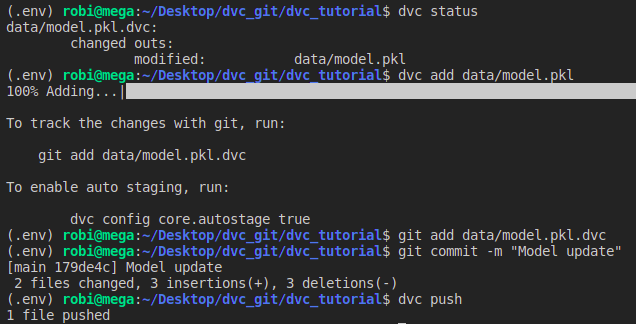
python src/train.py --train-path data/dataset.csv --n-estimators 50Using the dvc status command, you can check if any of the files you are tracking with DVC has been modified. In the example in the image, the model.pkl file was modified.
You need to run the dvc add command again to update the file to the latest version and use the dvc push command to save the changes to the Drive. In addition, changes need to be recorded in the Git.
What if we realize that we don’t like the new version of the model and would like to go back to the previous version? No problem. First you need to git checkout the model.pkl.dvc file to the previous one and then perform a dvc checkout to change the version of the model.
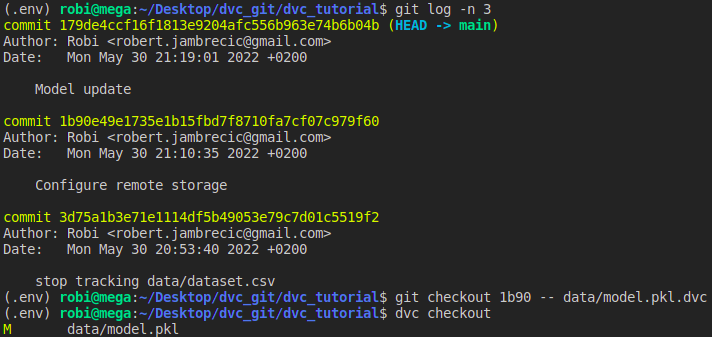
In the same way we can use DVC to work in different branches. For example, we have two branches and in each we use a different data set and a different model. After we change the branch, we only need to perform a dvc checkout in order to switch to the desired version of the data. All the versions we have downloaded will be cached so the transition from one version to another will be extremely fast.
DVC pipelines
In the current project we have the following structure.
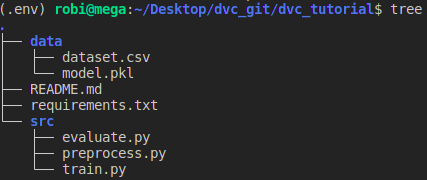
The usual course of the machine learning model pipeline would be preprocess -> train -> evaluate.
- preprocess.py – takes the data set data/dataset.csv and creates a processed data set for training data/dataset_train_preprocessed.csv and a data set for testing data/dataset_test_preprocessed.csv
- train.py – trains the model using the training data set and saves the trained model to data/model.pkl
- evaluate.py – tests the model on a test set and creates a file with metrics data/evaluate.csv
In this example, we can use the DVC pipeline and define which stage will be executed in which case. The pipeline stage is defined by using the dvc run command, -n indicates the name of the stage, -d the file upon which the stage depends, -o the output file, and -M the output file in which the metrics are defined.
Before we get started, we need to remove the versioning of dataset.csv and model.pkl files from the previous example:
dvc remove data/model.pkl.dvc data/dataset.csv.dvc
git add data/model.pkl.dvc data/dataset.csv.dvc
git commit -m "Remove dataset.csv and model.pkl versioning"The preprocess stage depends on the preprocess.py and dataset.csv scripts. In the event that one of these two files is modified, the following command will be executed python src/preprocess.py
dvc run -n preprocess \
-d src/preprocess.py -d data/dataset.csv \
-o data/dataset_train_preprocessed.csv -o data/dataset_test_preprocessed.csv \
python src/preprocess.py The train stage depends directly on src/train.py and data/dataset_train_preprocessed.csv and indirectly on src/preprocess.py and data/dataset.csv. In the event that one of these four files is modified, the following command will be executed python src/train.py
dvc run -n train \
-d src/train.py -d data/dataset_train_preprocessed.csv \
-o data/model.pkl \
python src/train.pyThe evaluation stage depends directly on src/evaluate.py and data/dataset_test_preprocessed.csv and indirectly on src/preprocess.py, data/dataset.csv and data/model.pkl. In the event that one of these five files is modified, the following command will be executed python src/evaluate.py
dvc run -n evaluate \
-d src/evaluate.py -d data/dataset_test_preprocessed.csv -d data/model.pkl \
-M data/evaluate.csv \
python src/evaluate.pyAfter executing the previous three commands, the dvc.yaml and dvc.lock files will be created. The dvc.yaml file defines all stages of the pipeline and defines for each of them the execution command, dependencies and output files.

The dvc.lock file defines the versions of all files that were used when the pipeline was last launched.
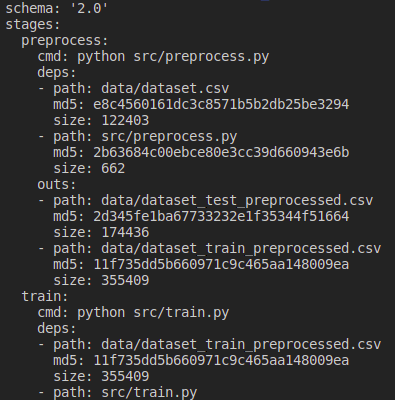
The dvc repro command starts all stages in which the stage dependency files have been modified since the last execution (i.e. the MD5 summary of these files has changed).
If there have been no modifications to files tracked by DVC and we run dvc repro, no stage will be executed.

For example, if we change the model in the train.py script and run dvc repro, the training and evaluation stage will be started.
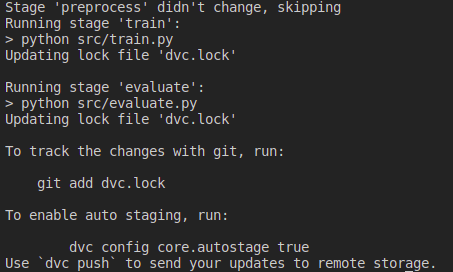
Conclusion
In this blog, we showed how you can use DVC to version data within the Git project. Instead of backing up files before making any changes, you can let DVC do the job, and you can go back to the version you want at any time. Also, the DVC can speed up your data-driven pipeline by executing only the stages in which the changes occurred.

