Blog ENG
The history of computer vision and the evolution of autonomous vehicles
Computer vision is one of the fields of artificial intelligence which was developed from digital image processing, and whose focus is enabling computer systems to retrieve information from images and to understand images in the same way humans do.
History
Although the biggest growth happened recently, in 2012, when a neural network called AlexNet won the ImageNet visual recognition competition and paved the way for neural networks to dominate the field of artificial intelligence, research of the field is much older. AlexNet is nothing more than a version of a design from 1989, which is a variant of an even older design from 1979.
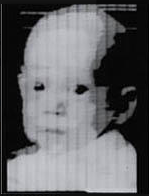
Work on computer image processing started much earlier, in 1957, at the American National Institute for Standards and Technology, where a group of engineers, led by Russell Kirsch, succeeded in making the first ever digital scan of an image. The image they used was of Russell’s infant son, which became so famous that the Life magazine included it in its article about 100 images that changed the world. The original image is being kept in the Portland Art Museum.
At the same time, in 1959, two neurophysiologists, David Hubel and Torsten Wiesel, became interested in the way in which the brain interprets visual stimuli. They decided to do an experiment on the cat’s primary visual cortex. Using electrodes, they studied the activation of neurons while showing images to the cat. They concluded that there exist simple and complex neurons and that visual processing starts with simple structures (lines and edges). British neuroscientist David Marr extended their work in 1982. He claimed that the process of visual recognition has a hierarchical structure, starting with recognizing fundamental concepts and then building a tridimensional map of the image. Those hypotheses were used as building blocks of the first visual recognition system.
Lawrence Roberts is generally considered the father of computer vision. In his doctorate thesis in 1963 at MIT, he presented a process for getting information about a 3D object from a 2D image. He is also interesting because he later went to work for DARPA and took part in developing the Internet.
In 1966 a professor at MIT’s laboratory for artificial intelligence, Seymour Papert, gave his students a summer project in which they were tasked to develop a system for automatic discerning of foreground and background, and extracting objects from real-life images. The project wasn’t a success but many consider this a start of computer vision as a scientific field.
A step towards current methods was made in 1979, when a Japanese computer scientist Kunihiko Fukushima develops an artificial network for pattern recognition, which was made from convolutional layers. They were revolutionary because they treated a part of image as a whole and in that way they didn’t ignore mutual dependence of neighboring pixels. He called it Neocognitron and it is undoubtedly the origin of networks which are even currently dominating the world of automatic visual recognition.
Ten years later, in 1989, French computer scientist Yann LeCun uses a famous training algorithm on a network based on Neocognitron and successfully applies it for reading and recognizing postal codes. He is also responsible for one of the most famous datasets in Machine learning, the MNIST dataset of handwritten digits.
The biggest advance happened in the aforementioned year 2012, when AlexNet drastically reduced the error rate in object classification on the ImageNet dataset. The ImageNet dataset was made in 2010 because of the evolution in algorithms for image processing. It consists of more than a million images divided into 1000 classes of everyday objects (animals, types of balls, modes of transport, etc.). Today’s precision for computer systems is more than 97%, while human precision is around 95%.
Autonomous vehicles
The biggest topic discussed currently concerning computer vision is certainly autonomous vehicles. The task of autonomous driving is complicated because driving is one of the most complex actions humans perform regularly, but that didn’t stop scientists working on it.
In 1925 Francis Houdina demonstrated an automobile controlled by radio signals from another car which was following it.
During the space race in 1961 scientists began working on a way to land and control vehicles on the moon. That resulted in the Standford Cart, a vehicle made by James Adams which used cameras for locating and following a line drawn on the road. It was the first use of cameras in autonomous vehicles, a practice which is common today.
In 1995 scientists from the Carnegie Mellon University drove their minivan from Pittsburgh to San Diego (a distance of 4 501 km). They controlled the speed and breaking, but they didn’t steer.
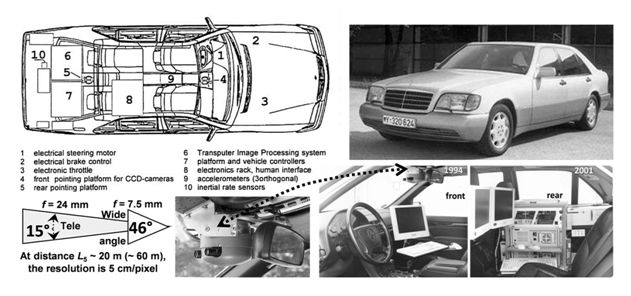
The first fully autonomous demonstration happened in 1994 in Paris. A team, led by German computer scientist Ernst Dickmann, drove in two Mercedes 500 SEL cars. The cars drove over 130 km/h, changed lanes and reacted to vehicles around them, all without the help of people in them.
Nowadays Tesla is regarded as a pioneer. Its vehicles offer the Full Self-Driving package which allows the car to drive autonomously on the highway. The car gets its information about its surroundings from 8 cameras mounted in a way that gives it 360 degrees of view around the car and at a distance of 250 meters.

Conclusion
Despite the impressive growth of computer vision and its interesting history, especially regarding the speed of development of autonomous vehicles, there are many problems still unsolved. Unfortunately, because of the difficulty of the task there are still no fully autonomous cars, but a lot of the results acquired through research are used in ADAS (Advanced Driver Assistance System) today, which enhances road safety.


{kind=link}