Blog
Transformeri: obratite pozornost
Kakve veze Megan Fox i Michael Bay imaju sa strojnim učenjem?
Ne, ovo nije kritički osvrt na filmski klasik. Transformeri od 12. lipnja 2017. godine više nisu samo kul automobili koji se pretvaraju u robote.
Izlaskom Googleovog znanstvenog rada “Attention is all you need”, riječ “transformer” doživljava renesansu u tehnološkoj zajednici i dobiva sasvim novo značenje.
Transformeri su, prema svojoj novoj inkarnaciji, naziv za arhitekturu modela dubokog učenja. I to vrlo revolucionarnu. Zavirit ćemo u njihov svijet i pogledati što ih to čini primjenjivima, zanimljivima, pa čak i superiornima u moru arhitektura modela dubokog učenja koje nikada nije bilo dublje. Osvrnut ćemo se i na trendove u strojnom učenju koje su pokrenuli.
Duboko učenje, povratne neuronske mreže, mehanizam pozornosti
Osnovna ideja koju transformeri koriste jest mehanizam pozornosti. Njihova priča od samog početka vezana je uz područje obrade prirodnog jezika. Arhitekture modela dubokog učenja dizajnirane su da se, više ili manje, prilagode obliku ulaznog signala koji obrađuju. Ulazni signal kod obrade prirodnog jezika je u mnogim slučajevima niz riječi. Riječi se moraju na određeni način numerikalizirati te se na taj način koncept može poopćiti na obradu niza vektora brojeva. Prva arhitektura prilagođena obradi niza pomoću dubokog učenja su povratne neuronske mreže.
Glavno obilježje povratnih neuronskih mreža koje se pretvorilo u njihov glavni problem jest slijedna obrada niza. Slijednom obradom osigurava se da model vidi informacije ekstrahirane iz n-1 prijašnjih elemenata prilikom obrade n-tog elementa niza.
Cijena ovakvog pristupa jest usporavanje procesa obrade u odnosu na paralelnu obradu cijelog niza. Prirodni jezik osim svoje kompleksnosti ima i svojstvo velikih duljina nizova koje treba obraditi u nekim slučajevima, poput problema klasifikacije novinskog članka. Kombinacija ovih svojstava i pojave gubitka poveznica među udaljenim elementima niza učinila je povratne neuronske mreže teško upotrebljivima.
Mehanizam pozornosti iskorišten je kao nadogradnja povratnih neuronskih mreža koja bi trebala pomoći kod problema gubitka informacija prilikom obrade duljih nizova. Pojednostavljena ideja mehanizma pozornosti je da se, u trenutku obrade elementa niza, računanjem dinamičkih težina određuje na koje druge elemente niza treba obratiti najviše pažnje (pozornosti). Prve primjene ovog mehanizma vezane su uz probleme obrade i generiranja niza (seq2seq – niz u niz modeli), poput strojnog prevođenja.
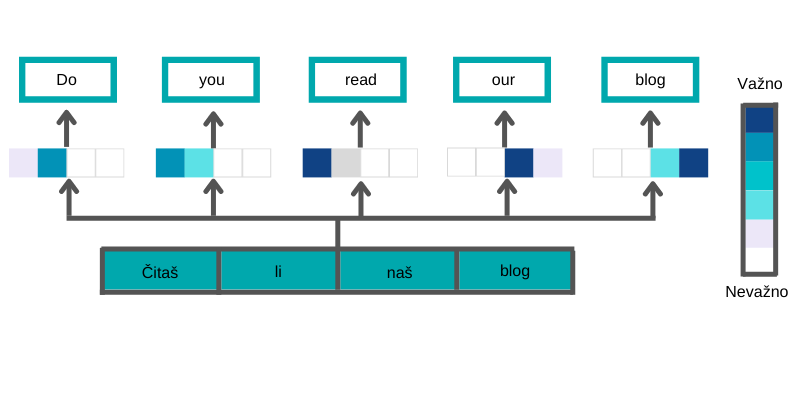
Vidimo kako mehanizam pozornosti ekstrahira kontekst iz ulaznog niza (originalne rečenice) i tako stvara vrijedne informacije korisne za generiranje izlaznog niza (prijevoda). Primjerice, prilikom generiranja riječi “read” maksimalna pozornost usmjerena je prema riječi “čitaš” te je zato najintenzivnije obojan prvi kvadratić.
U slučaju riječi “you”, pozornost je usmjerena na riječi “čitaš” i “li” jer one daju informaciju o licu glagola itd. Ovaj intuitivni i jednostavni koncept postigao je jako velik uspjeh nakon poopćenja i prilagodbe za primjenu na drugačije zadatke.
“Pozornost je sve što nam je potrebno”
Google je u “Attention is all you need” napravio ono što sam naslov govori. Odbacili su povratne neuronske mreže i koncipirali čitav model oko mehanizma pozornosti. U Googleovoj verziji mehanizam pozornosti ne povezuje ulazni i izlazni niz, već samo obrađuje ulazni niz. Koncept je nazvan samo-pozornost. Detaljnije objašnjenje mehanizma samo-pozornosti temelji se na tri ključne riječi: upit, ključ i vrijednost.
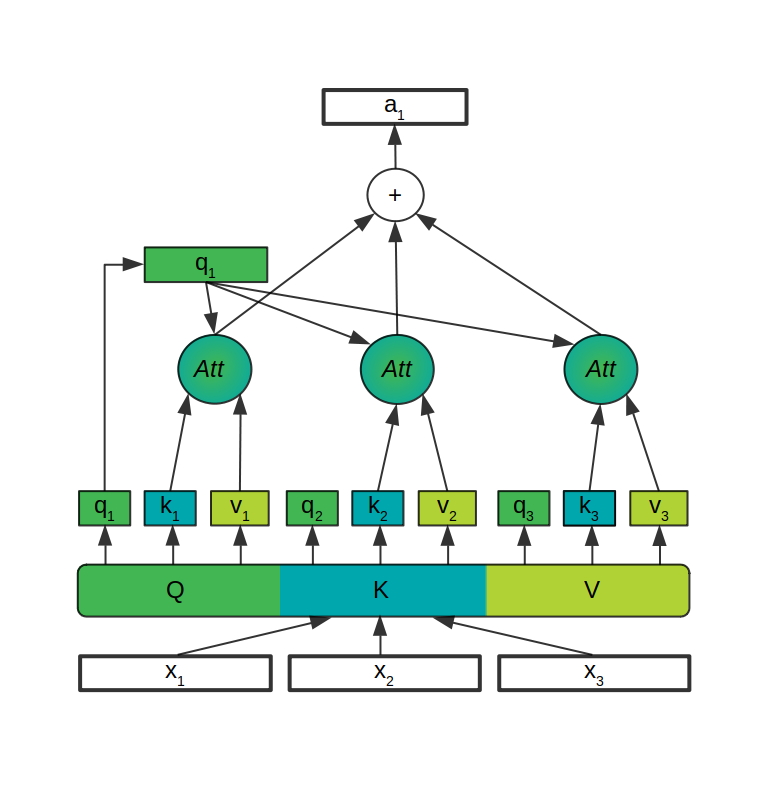
Upit, ključ i vrijednost su različite transformacije istog ulaznog vektora (elementa niza) pomoću Q, K i V matrica čije se vrijednosti uče prilikom treniranja modela. Nakon što se iz ulaznog vektora (x na slici) za svaki element niza transformacijama generiraju upit, ključ i vrijednost (q, k, v na slici), računa se pozornost za pojedinačne elemente.
Nadalje, pozornosti pojedinačnog elementa niza određuje se množenjem upita tog elementa s ključevima svih elemenata niza. Nakon skaliranja i primjene funkcije softmax koja pretvara rezultate prve operacije u oblik vjerojatnosne distribucije, dobiveni vektori množe se s vektorima vrijednosti za svaki element niza. Cijeli proces na slici je označen samo s Att.
Suma rezultata ove operacije za svaki element niza jest vektor pozornosti za taj element (a na slici). Postupak se ponavlja za svaki element.
Zašto transformeri?
Zašto je ova zapetljana formulacija s tri različite transformacije istog ulaznog niza i naoko jednostavnim izrazom koji ih povezuje uopće uspješna?
Koncept mehanizma samo-pozornosti je zanimljiv jer ima dijeljene matrice s različitim svrhama koje se mogu učiti. Jednostavna jednadžba koja ih povezuje također je vrlo bitna zbog toga što je samo-pozornost intuitivno opisati matričnim množenjima koja su osnovna transformacija u strojnom učenju. No prava ljepota transformera jest u odličnom dizajnu arhitekture koja maksimalno dobro može iskoristiti prednosti mehanizma samo-pozornosti.
Prvo, samo-pozornost je proširena korištenjem više različitih skupina upit-ključ-vrijednost matrica kako bi se one mogle specijalizirati za različite zadatke.
Potom, koncept je podignut na razinu iznad ponovnom primjenom samo-pozornosti na već izračunate vrijednosti samo-pozornosti. Ovim postupkom prvo se računa pozornost između riječi, nakon toga između parova riječi, a zatim između parova parova riječi itd. Zbog boljih performansa prilikom treniranja dodano je skaliranje izlaza, te rezidualne konekcije koje preskaču određene elemente arhitekture i omogućavaju bolji protok informacija kroz model. Sve ove odluke prilikom dizajna arhitekture transformera napravljene su s ciljem bržeg, efikasnijeg i stabilnijeg treniranja modela.
Posljednja velika prednost transformera jest mogućnost paralelne obrade niza, nasuprot slijedne obrade jednog po jednog elementa kod povratnih neuronskih mreža.
Sve ove karakteristike učinile su transformere idealnima za preuzimanje state-of-the-art trona u području obrade prirodnog jezika. Nedvojbeno, brza obrada primjera prilikom treniranja napokon je omogućila efikasnu primjenu velikih modela na velike i nestrukturirane skupove podataka.
Ograničenja pretvorena u prednosti
Transformeri zahtijevaju velik skup podataka za početno treniranje te je u takvim slučajevima teško pronaći zadatak u kojemu su toliki skupovi dostupni.
Iz tog razloga, prvi transformeri trenirani su na zadatku modeliranja jezika (language modeling). U osnovi, modeliranje jezika sastoji se od predviđanja sljedeće riječi u rečenici.
Rješavanjem ovakvog zadatka na velikom broju primjera, model na apstraktnoj razini uči pravila i kontekst jezika. Transformeri na raznim, većinom otežanim verzijama ovog zadatka uz mogućnost obrade brojnih primjera te ulaganja velikih sredstava u treniranje, postižu vrhunske rezultate.
Ono što je fascinantnije od dobrih rezultata jest sama sposobnost da transformeri, koji su u potpunosti istrenirani na zadatku modeliranja jezika, uz dodatno treniranje na drugim zadacima u području obrade prirodnog jezika, postignu odlične rezultate čak i na njima. Sam postupak dotreniranja modela za zadatak za koji nije originalno treniran, naziva se preneseno učenje.
Prednosti – preneseno učenje i skalabilnost
Izvrsni rezultati postignuti prenesenim učenjem transformera na raznim zadatcima i dostupnost predtreniranih modela doveli su do zanimljivog razvoja u području dubokog učenja. Sada je moguće korištenjem par linija koda dohvatiti model razvijen od strane tehnoloških divova i vrijedan milijune dolara te ga primijeniti na neki od osnovnih zadataka u području obrade prirodnog jezika.
Uz više truda i dodatnu infrastrukturu, ovaj isti model može se dotrenirati za željeni zadatak. Najpopularniji transformer koji se koristi na ovaj način je BERT.
Transformeri su pokazali zavidnu razinu otpornosti na probleme koje su ostale arhitekture modela pokazale kod skaliranja na veći broj parametara. Veličinu modela najjednostavnije je mjeriti brojem parametara – brojeva koji se uče u sklopu treniranja modela.
Mogućnost efikasnog treniranja jako velikih modela dovela je do konstantnog rasta broja parametara modela od dolaska transformera. Jedan od razloga ovog porasta jest i svojevrsno “moj model je veći od tvog” natjecanje među predvodnicima područja. Na slici su prikazani trenutno najveći modeli te je istaknut jasan trend rasta.
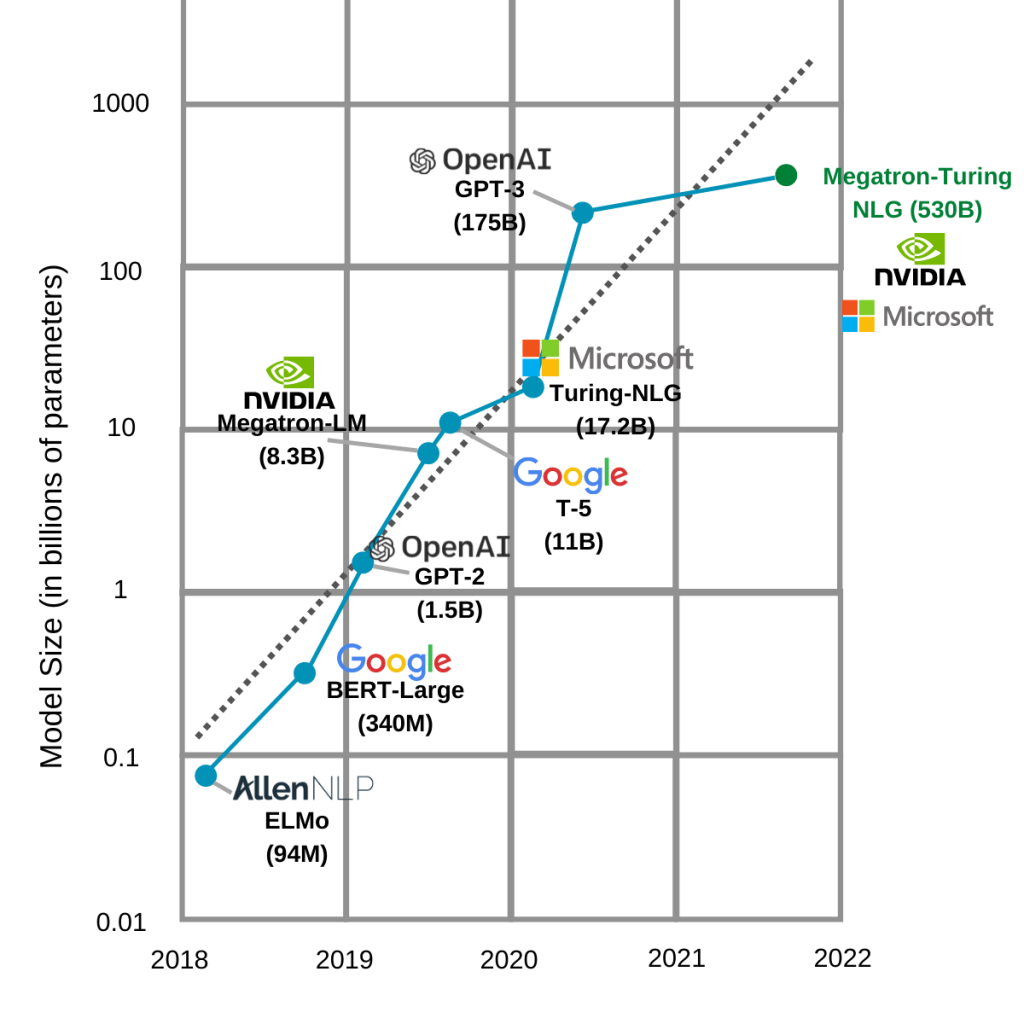
Can we make it bigger?
Vidimo da najveći model na ovom grafu ima nevjerojatnih 530 milijardi (530,000,000,000) parametara.
Do dolaska transformera mahom su najveći modeli bili konvolucijske neuronske mreže koje se koriste u području računalnog vida. Za usporedbu EfficientNet, moderna arhitektura konvolucijske neuronske mreže koju koristi naš tim za računalni vid na projektu SOVA, ima oko 8 milijuna parametara. To je 10 puta manje od najmanjeg modela i oko 65 000 puta manje od najvećeg modela prikazanog na slici.
Važno je napomenuti da najveći od ovih modela nisu koncipirani tako da budu pogodni za preneseno učenje, već su od početka trenirani za više zadataka. Zadatci kojima se bave najveći modeli vezani su pretežno uz generiranje teksta. Neki modeli sa slike – GPT-3 (OpenAI) i Megatron-Turing (Microsoft) – nisu javno dostupni. Jedan od razloga jest i to što im nije potrebno dotreniranje. Drugi je ogroman broj parametara (veličina) koji ih čini neupotrebljivima bez teško dostupne infrastrukture. Treći je njihova state-of-the-art kvaliteta u specifičnim zadatcima generiranja teksta. Nedostupnost ovakvih transformera rezultirala je njihovim korištenjem samo u rješenjima u oblaku. Tako je GPT-3 trenutno dostupan isključivo preko plaćenog API-ja na kojemu ga je moguće isprobati i koristiti.
Transformers <3 NLP
Obrada prirodnog jezika i transformeri su par iz snova.
Veliki, nestrukturirani skupovi podataka i riječi kao glavni elementi koji se pretvaraju u vektore značajki malih dimenzija, uveli su transformere u duboko učenje na velika vrata. Doba informacija s tekstom kao jeftinom sirovinom dalo je izvrsne temelje modelima s velikom gladi za podacima. Zadatak modeliranja jezika je omogućio generiranje velikog broja primjera za učenje bez potrebe za označavanjem od strane čovjeka.
Tako je dobiveno more podataka potrebno da nahrani glad početnih transformera i pokaže da ovi modeli mogu pomicati granice. Od tada pa nadalje, razvijene su razne verzije transformera čije su implementacije dostupne svima. Prošle godine su Googleovim Vision Transformerom transformeri svoj utjecaj proširili i na drugo veliko područje – računalni vid.
Do transformera, preneseno učenje bilo je popularan trend, ali s transformerima je dobilo svoje heroje. Iznimno su zahtjevni za treniranje od nule i začuđujuće efikasni i uspješni kada se dotreniraju za specifične zadatke.
Huggingface – infrastruktura za strojno učenje današnjice i budućnosti
Trend primjene prenesenog učenja na transformere doveo je do razvoja nove vrste infrastrukture i dodatnog pojednostavljivanja dubokog učenja iz perspektive potrebne količine koda i same dostupnosti unaprijed razvijenih komponenti potrebnih za razvoj projekta.
Infrastruktura se u ovom slučaju odnosi na Huggingface, zajednicu koja se bavi čitavim spektrom zadataka potrebnih za razvoj projekata u strojnom učenju. Huggingface nudi i razne predtrenirane transformere preko knjižnice otvorenog koda transformers koju održava. Revolucionarnost ovog pristupa jest u činjenici da je pomoću Huggingfaceove knjižnice otvorenog koda moguće preuzeti svaki od dostupnih transformera, dotrenirati ga i ponovno postaviti na njihov oblak kako bi bio dostupan ostalim korisnicima. Ovakva procedura se primjenjivala na razne modele, ali nikada do sada nije bila ovako standardizirana i jednostavna. Huggingface se uspio pozicionirati kao centralna lokacija za dijeljenje transformera, također nudeći podršku za istraživanje, razvoj i serviranje modela.
Proces jednostavnog preuzimanja modela koji se bave generaliziranim zadatcima rješava dosadašnje probleme dostupnosti i dijeljenja modela unutar zajednice. Najnoviji i najbolji modeli su trenutno preveliki i nisu otvoreni za sve, ali odmah do njih nalaze se brojni state-of-the-art transformeri koji samo čekaju da ih se primjeni na razne probleme.
Revolucionarna arhitektura u kombinaciji s razvojem sklopovlja za treniranje već je pokrenula novi trend rasta – i to doslovnog – u području strojnog učenja.
Literatura
Attention Is All You Need, Vaswani et al., 2017., https://arxiv.org/abs/1706.03762
Large Language Models: A New Moore’s Law?, Julien Simon, 2021., https://huggingface.co/blog/large-language-models
Using DeepSpeed and Megatron to Train Megatron-Turing NLG 530B, the World’s Largest and Most Powerful Generative Language Model, Paresh Kharya & Ali Alvi, 2021., https://developer.nvidia.com/blog/using-deepspeed-and-megatron-to-train-megatron-turing-nlg-530b-the-worlds-largest-and-most-powerful-generative-language-model/
An Image is Worth 16×16 Words: Transformers for Image Recognition at Scale, Dosovitskiy et al., 2021., https://arxiv.org/abs/2010.11929
Why Transformers Play A Crucial Role In NLP Development, Ram Sagar, 2019., https://analyticsindiamag.com/why-transformers-play-a-crucial-role-in-nlp-development/

