Blog ENG
Transformers: Pay attention
What do Megan Fox and Michael Bay have to do with machine learning?
No, this is not an analysis of the successful film series. From the 12th of June 2017 transformers are not only those cool cars turning into robots. With the publication of Google’s scientific paper “Attention is all you need”, the word “transformer” is rediscovered by the tech community as it gains yet another meaning.
Transformers are, in their newest form, a type of deep learning model architecture. A revolutionary type. We are going to take a peek into their world and discuss what makes them applicable, interesting, and even superior in a sea of deep learning model architectures that have never been deeper. We’ll also put them in the perspective of current trends in machine learning.
Deep learning, recurrent neural networks, attention mechanism
The basic architecture of transformers is based on the attention mechanism. From the beginning, the story of transformers is told in the field of natural language processing (NLP). Deep learning model architectures are designed to adapt to the shape of the input signal. In NLP, an input signal is often a sequence of words. Words have to be numericalized to be processed by an algorithm, so the problem can be generalized to the level of processing a sequence of vectors. Recurrent neural networks (RNNs) are a deep learning architecture designed to process sequential data.
The main feature of RNNs, which turned into their main downside, is the serial processing of a sequence. By processing a sequence element by element, information gained from processing the first n-1 elements of the sequence is available when processing the n-th element of the sequence. The cost of this approach is a drop in time efficiency in comparison to parallel processing. NLP tasks often feature long sequences of complex elements (words). An example of such a task would be newspaper article classification. The combination of these properties and the problem of memorizing connections between distant sequence elements has seriously limited the application of RNNs.
The attention mechanism was first used to solve the long-term dependency (memorizing distant connections) problem. A simplified explanation of attention would be calculating dynamic weights among sequence elements that will help determine which elements of the sequence should be give the most attention to when processing a single element. In the beggining attention was applied to problems in the domain of text generation (seq2seq), such as machine translation.
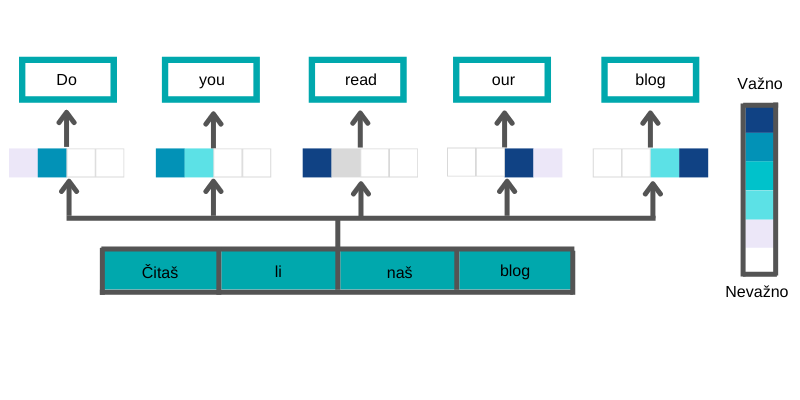
In this example, we see how the attention mechanism extracts information from the input sequence (original sentence) and then uses that information when generating the output sequence (translated sentence). To explain, we see that when the word “read” is generated most attention is given to the word “čitaš” so the first square has the most intensive color.
For the word “you”, attention is given to the words “čitaš” and “li” because they contain information about the person of the verb. This intuitive and simple concept has achieved a lot of success after it was generalized and adopted for applications in other tasks.
“Attention is all you need”
In their paper “Attention is all you need”, Google did exactly what they said in the title. They got rid of RNNs, kept only the attention mechanism, and built a model around it. Google’s version of the attention mechanism does not connect the input and the output sequence. Instead, it only processes the input sequence and determines attention between its elements, hence the name self-attention. A more detailed explanation of the self-attention mechanism is based on three words: query, key, and value.
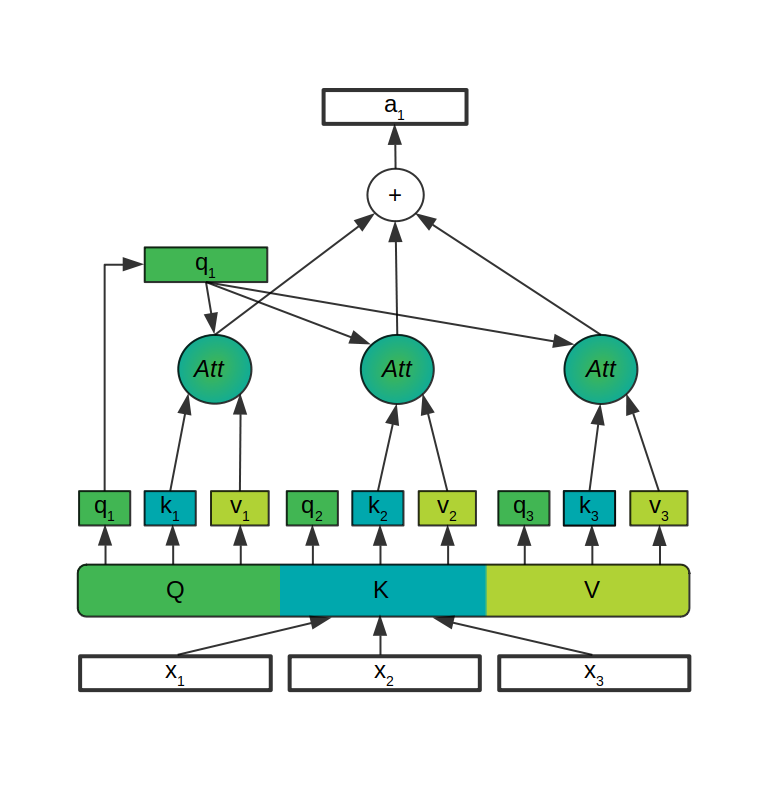
Query, key, and value are different transformations of the same input vector (element of the sequence) made using the Q, K, and V matrices with trainable parameters. After generating the query, the key, and the value (q, k, v on the image) from the input vector (x on the image) of each element of the sequence, the attention is calculated for each element.
Furthermore, the attention of each element is determined by multiplying its query with the key of each element in the sequence. After scaling and applying a softmax function to yield a probability distribution from the results of the first operation, probabilities are multiplied with the value vectors for each element of the sequence. All of this is marked as the Att circle graphic on the image. The sum of the resulting vectors is the attention vector (a on the image) for the element used to generate the initial query vector. The same process is applied to each element of the sequence.
Why transformers?
Why is this confusing formulation with three different transformations of the same input and a simple equation that connects those transformations even successful?
Well, the concept of self-attention is interesting because it has shared matrices with different purposes and trainable parameters. A simple equation that connects those matrices is very important because it’s intuitive to formalize self-attention in matrix multiplications which are the basic and most popular transformations in machine learning. But the real beauty of transformers is the very well-designed architecture that can exploit all the advantages of the self-attention mechanism.
Firstly, self-attention is expanded by using multiple different query-key-value matrices so they could specialize in different tasks.
Secondly, the whole concept is elevated to another level by applying self-attention to the output of the last self-attention. This enables calculating the attention between words in the sequence, then between pairs of words, then between pairs of pairs of words, etc. To ensure better training performances output is scaled and residual connections are added to skip certain parts of the model and allow a better flow of information through the model. All of these decisions were made to create a model with faster, more stable, and more efficient training performance.
Transformers use parallel processing of the input sequence, which is, as we established earlier, very important in terms of speed.
All of these features have made transformers the best candidates to take over the state-of-the-art throne in NLP. Faster processing time allowed for a faster training time and it led to efficiently applying large models on large and unstructured datasets.
Turn the weaknesses into strengths
Transformers need a large dataset for the initial training, which makes it hard to find an adequate dataset to train them on.
For that reason, the first transformers were trained on a language modeling task. In essence, language modeling means predicting the next word in a sentence. By solving this task on a large number of examples, models learn language rules and context on an abstract level. Transformers achieve excellent results on different, more difficult variations of this task.
What is even more fascinating is that, after being trained on the language modeling task, transformers achieve great results on various other tasks with little training in those specific tasks. The process of fine-tuning a model on a task for which it was not originally trained is called transfer learning.
Advantages – transfer learning and scalability
Great results achieved on various tasks with a transfer learning approach paired with the availability of the pre-trained transformer models have led to an interesting development in the field of deep learning. Now you can, with a few lines of code, download a model developed by the tech giants which cost a million bucks to train and use it on a variety of basic NLP tasks. With a little more effort and some additional infrastructure, the same model can be fine-tuned for a chosen task. The most popular transformer used in this way is BERT.
Transformers have also showed an admirable level of resilience to the problems other architectures showed when being scaled to larger parameter numbers. The model size can most easily be described by the number of parameters – numbers that are learned while training the model. The possibility of efficiently training very large models has led to the constant growth of model sizes from the emergence of transformers. One of the reasons for this growth is also a “my model is bigger than yours” competition between the field leaders. The next image shows the sizes of the biggest models and the trend can be easily noticed.
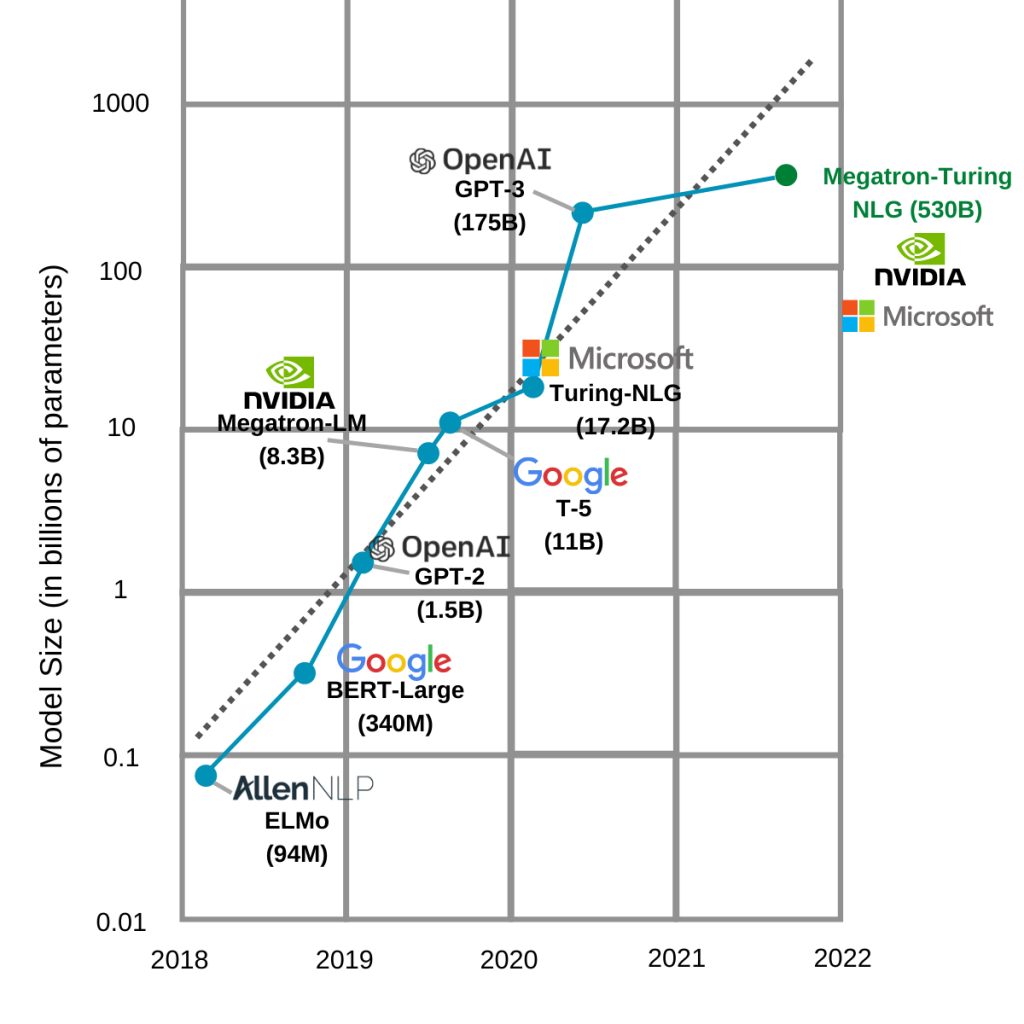
Can we make it bigger?
As we can see, the biggest model on this graph has 530 billion (530 000 000 000) parameters.
Before transformers, the biggest models were mostly convolutional neural network (CNN) architectures used in the field of computer vision. EfficientNet, a modern CNN architecture used by our computer vision team on the SOVA project has around 8 million parameters. That’s 10 times less than the smallest, and around 65 000 times less than the biggest model shown on the graph.
It is important to mention that the biggest of these models are not designed for transfer learning, but rather trained on a large variety of tasks from the beginning. The biggest models are also made for tasks of text generation, not text classification. Some of the models from the image – GPT-3 (OpenAI) and Megatron-Turing (Microsoft) – are not publicly available. One of the reasons is that they are not made to be fine-tuned. Another reason is their incredible size which makes them unusable without accompanying infrastructure. The last reason is probably their state-of-the-art quality on specific text generation tasks. The unavailability of these models has resulted in them being made available through cloud solutions. For example, GPT-3 is currently available only through a paid API where you can test and use it.
Transformers <3 NLP
Transformers and NLP are a match made in heaven.
Big, unstructured datasets and words as the main building blocks that can be turned into low dimension feature vectors have allowed transformers to enter deep learning with a splash. The information age with text as the most available form of information has given a great foundation for developing data-hungry models. The language modeling task was used to generate large numbers of training examples without a need for human labeling.
These were all the requirements that had to be met to feed the hunger of the first transformers and show the community they can push limits. From then on, multiple versions of transformers were developed and most of them have been open-sourced. Last year with their Vision Transformer, Google spread the influence of transformers to another big field of AI – computer vision. Before transformers, transfer learning was a popular and growing trend, but with transformers, it has gotten its heroes. They are very challenging and expensive to train from the beginning and astonishingly efficient and successful when fine-tuned to specific tasks.
Huggingface – ML infrastructure for the present and the future
The trend of applying transfer learning to transformers has led to the creation of a new type of infrastructure and additional simplification of deep learning in terms of coding and availableness of out-of-the-box components needed to develop a project.
When I say infrastructure I mean Huggingface, a community that maintains a platform that offers support in a wide range of tasks that are part of developing a machine learning project. Huggingface offers various pre-trained models through their transformers library.
This is a revolutionary approach because Huggingaface’s library allows you to download any of the available transformers, fine-tune it, then upload it back to their hub to be used by everybody. This procedure has already been applied to various model architectures before, but it has never been made so straightforward. This positioned Huggingface as a central hub for sharing models, offering a lot of support for research, development, and serving of the models on the way.
The process of simply downloading a generalized pre-trained model solves a lot of model availability and sharing problems the community has been facing. The newest and the best models are currently too big and they are not always open-sourced, but right next to them there is a variety of state-of-the-art transformers just waiting to be applied to all sorts of problems. A revolutionary infrastructure combined with the development of training hardware has already started a new trend of growth – both figurative and literal – in machine learning.
Literature:
Attention Is All You Need, Vaswani et al., 2017., https://arxiv.org/abs/1706.03762
Large Language Models: A New Moore’s Law?, Julien Simon, 2021., https://huggingface.co/blog/large-language-models
Using DeepSpeed and Megatron to Train Megatron-Turing NLG 530B, the World’s Largest and Most Powerful Generative Language Model, Paresh Kharya & Ali Alvi, 2021., https://developer.nvidia.com/blog/using-deepspeed-and-megatron-to-train-megatron-turing-nlg-530b-the-worlds-largest-and-most-powerful-generative-language-model/
An Image is Worth 16×16 Words: Transformers for Image Recognition at Scale, Dosovitskiy et al., 2021., https://arxiv.org/abs/2010.11929
Why Transformers Play A Crucial Role In NLP Development, Ram Sagar, 2019., https://analyticsindiamag.com/why-transformers-play-a-crucial-role-in-nlp-development/

