Blog ENG
Semantic search of documents
Searching for content is an activity that we all do regularly for private or business purposes, whether it’s searching databases, documents or web pages. Unlike searching paper documents, where the only way to find specific content is to read all the documents, with digitization we have greatly reduced the time and amount of performing such tasks.
Searching for digital content itself started very simply, with a search for exactly entered text (the so-called lexical search). Later it turned out that this type of search is not always efficient due to the richness and complexity of different languages. To make the search itself even better and more adapted to the search language, semantic search was introduced. By moving to the semantic search of documents, the search is performed not only by looking for the consistency of words in the document, but also by taking into account the meaning of the words themselves. The goal of semantic search is to improve the accuracy of search results by understanding the user’s intentions, the contextual meaning of the entered term, and the connection between the words themselves.
Lexical vs. semantic search
Lexical search only searches for exact word matches in a document or search database. We often use such a search, for example when we search a web page or a PDF document using the search command. In this case, we always have to be careful about the form of the word we are searching for, so we tend to write the root of the word to get all close searches.
If we imagine that we search for web content using the most famous web search engine Google, we would very quickly not be satisfied with the results that it throws up. Google allows us to try an exact word match if we write the query inside quotation marks, example in Figure 1. In this example, we can see that for the query “sale of apartments in Zagreb” (e.g. Croatian: Prodaja apartmana u zagrebu) the search engine would not throw out a single result, since there is not a single website that it has exactly such an expression written on it.
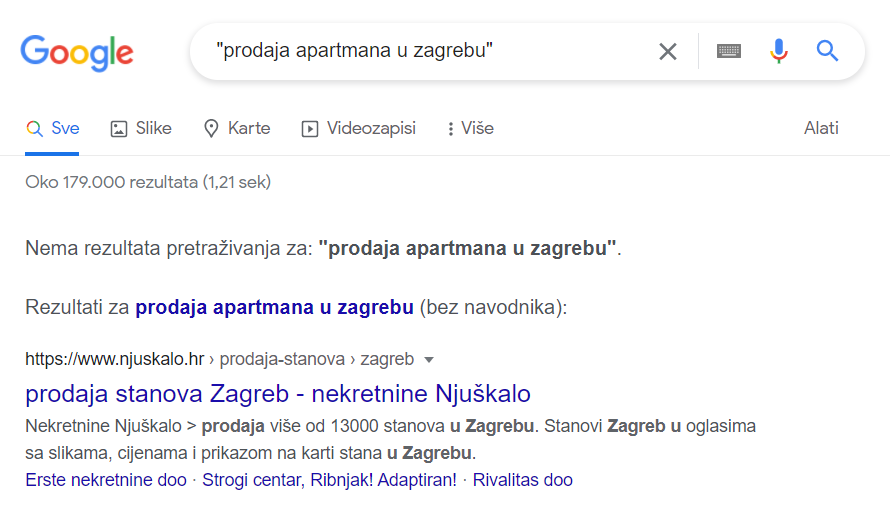
But since Google is a truly smart search engine, it automatically offers us to search for a query without quotation marks and find all the same and contextually similar, i.e. equal, queries. In such a case, we will get about 179,000 results. The reason for this is that in this case Google takes into account all synonyms, expressions, word orders and more to give the best result of our search. It is clear to us that if we ask for “apartment for sale in Zagreb” it is the same as asking for “apartment purchase in Zagreb”, “new apartment in Zagreb”, “real estate sale in the area of the city of Zagreb”, but how does Google know that? Or any other search engine? One of the answers lies in semantic search (Google and other advanced search engines use a number of other techniques when searching web pages, but this is not the topic of this blog, so we will not consider it in detail).
Semantic search components
One of the essential components of sematic search is sematic tagging. It enriches the content with information that can be further processed by linking existing information with isolated terms. These terms extracted from documents are unambiguously defined and linked to each other inside and outside the content. Semantic tagging is performed using Natural Language Processing (NLP) techniques that help translate and convert text into structured data.
In addition to semantic tagging, an important component in semantic search is also Latent semantic indexing (LSI). LSI is a NLP technique that analyzes the relationships between a set of documents and the concepts they contain by identifying hidden contextual relationships between words. In other words, LSI is based on the principle that words used within the same context have predominantly the same or related meaning even though they do not share the same characters or synonyms.
IBM Watson Discovery
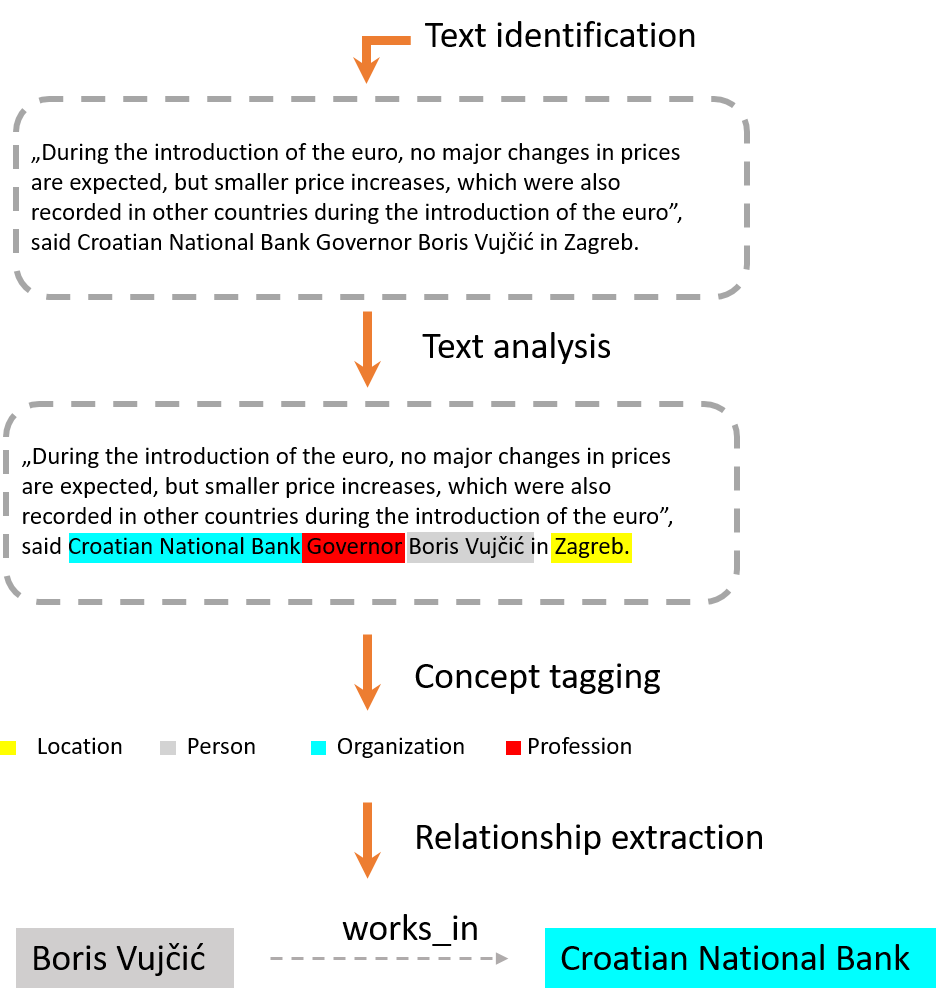
IBM Watson Discovery is IBM’s tool for intelligent semantic data search using artificial intelligence (AI). It is also a text analysis platform that uses NLP to discover useful data from complex business documents, websites or large data sets, thus shortening the search time itself. IBM Watson Discovery allows users to add their own sets of documents and then applies an algorithm that enriches the inserted data by extracting key concepts and entities (location, organization, person, etc.) and conducts semantic analysis of documents.
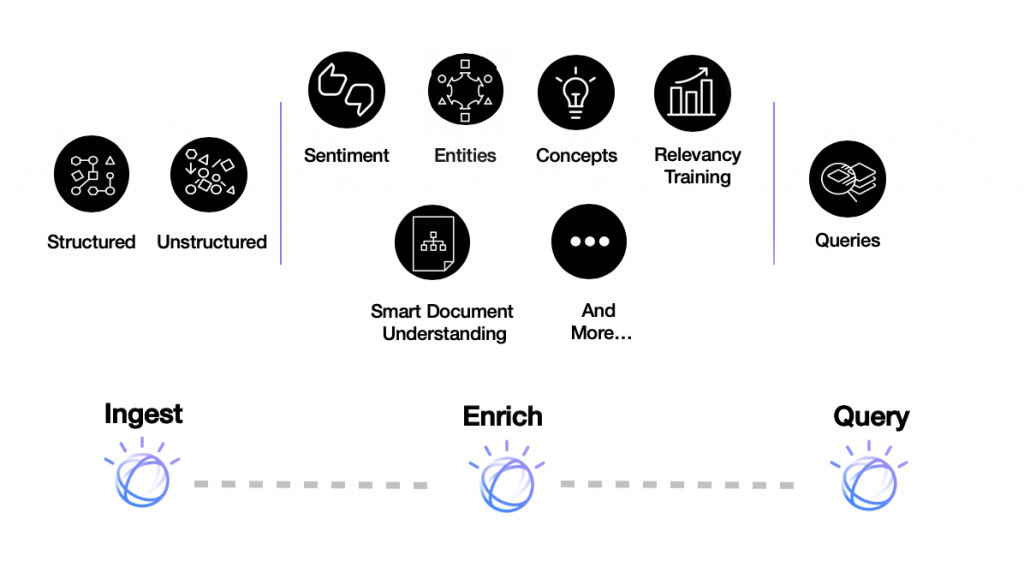
IBM Watson Discovery enriches data by adding metadata from collected semantic information. Data is collected using four main IBM Watson Discovery functions entity extraction, category classification, concept tagging and sentiment analysis. There is also an integrated Smart Document Understanding (SDU) tool. SDU is a tool based on machine learning algorithms that breaks documents into smaller pieces of information and allows users to easily categorize parts of documents so the tool can build better understanding of critical components within a given document and improve search results.

After data transfer and enrichment, it is possible to build queries and integrate IBM Watson Discovery into your own solutions or with other IBM tools such as IBM Watson Natural Language Understanding or IBM Watson Assistant. IBM Watson Discovery is implemented in IBM Watson Assistant via Search Skill and allows the virtual assistant to answer complex questions by browsing a large database of documents. IBM Watson Discovery is available in over 20 world languages, including Croatian, and can be used on-premises or in the cloud.
Conclusion
Semantic search has made it possible to search not only for matching words in documents, but also to search for the meaning of those words, i.e. queries. In other words, the goal of semantic search is to know why the user is searching for exactly those keywords and what he intends to do with the data obtained. This way of searching brings computer search of documents closer to the human way of thinking, taking into account different ways and tones of querying. Semantic search has revolutionized search engines, which is reflected in its widespread use not only in web browsers but also in knowledge base search engines for various fields of science and business.

